Service Meshes Decoded: Istio vs Linkerd vs Cilium
Compare the performance of Istio, Linkerd, and Cilium to choose the best service mesh for Kubernetes
Written by:
Published on:
Last updated on:
This blog is part of our Service Mesh series, we recommend reading the rest of the posts in the series:
- Service Meshes Decoded: Istio vs Linkerd vs Cilium
- Service Meshes Decoded: Is Istio Ambient worth it?
Service Mesh Introduction
A service mesh is a dedicated infrastructure layer that facilitates service-to-service communications between services or microservices using a proxy. Or, referring to Kelsey Hightower, we can say:
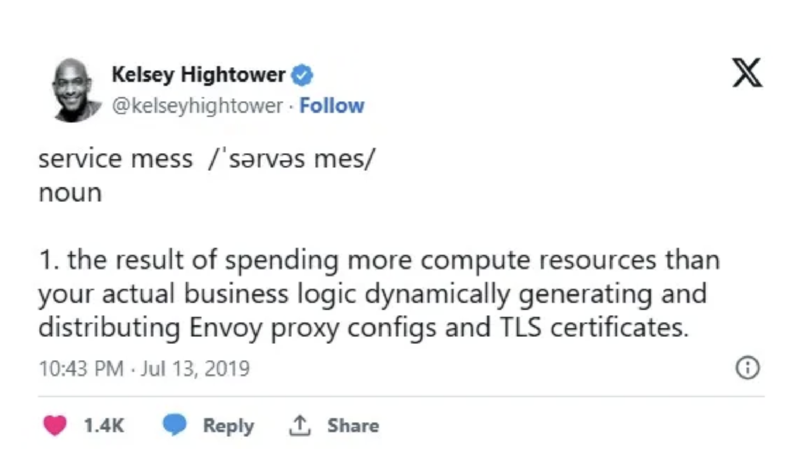
Figure - Kelsey Hightower redefines service meshes
If you are reading this blog post, I’m assuming you are already familiar with service mesh and are looking for a reliable comparison of the available options to determine the best. In this post, we will compare three popular open-source service meshes, Cilium, Istio, Linkerd and share our experience with their comparison.
To give some background, I was tasked with comparing these three meshes and preparing documentation to help LiveWyer understand each product in greater detail, comparing the pros and cons of the tested meshes.
This comparison covers the following areas:
- Deployment
- Configuration
- Maintenance
- Performance and Connectivity
- Operational Impact
- Compliance and Standards
Whilst this blog post only compares the performance of the three Service Mesh, the detailed test report and codebase are available in our POC Service Mesh 2024 repository.
This exercise will use our internal development platform, LWDE (Livewyer Development Environment), to expedite and simplify the environment setup process.
Environment Setup
A stable and consistent environment is crucial to ensure all comparison tests are accurate and fair. I adopted the following key principles to achieve this:
- Uniform environments for all products
- Consistent test tooling
- Identical test parameters and load
- Similar configuration and the same standards for all products
- Versions and configurations remain constant for the duration of the comparison test exercise
All tests were performed in separate, isolated environments. The environments consisted of an AWS EKS cluster with a tested product installed, and a separate VM was used for load generation on our test applications. Four environments were provisioned - one for the baseline and one for each service mesh. The environments were completely identical, deployed in the same region and availability zone. All versions and configurations across the environments were the same and remained unchanged throughout the tests. All clusters had four nodes of type c5.large, tainted respectively, to ensure scheduling was immutable across all the environments.
Below, you can see the diagram that shows the environment setup on the infrastructure level:
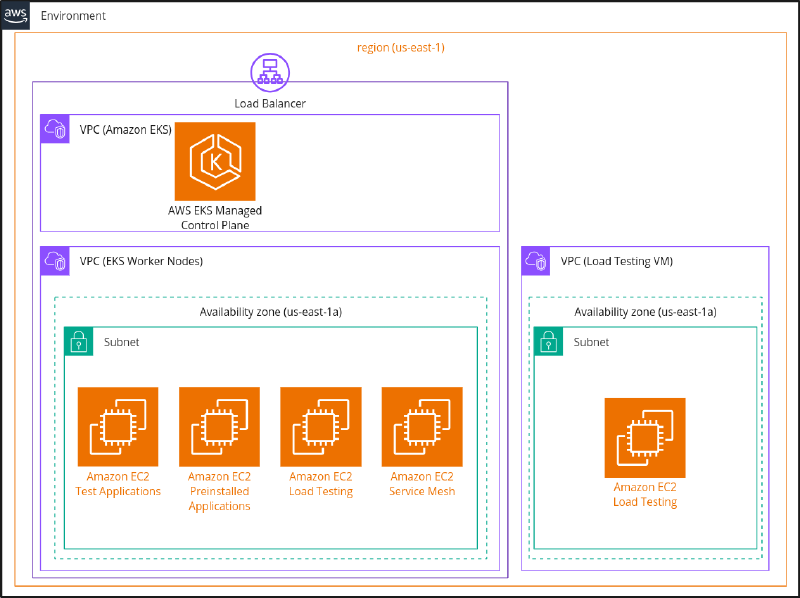
Figure - AWS network diagram
I created all the clusters using our LWDE. The LWDE makes it easy to manage clusters on different clouds, speeding up the creation and removal of the four clusters multiple times.
In terms of making the test fair from the product setup side, I performed the following actions:
- All products were installed using the latest stable version, and they are immutable during the tests
- All products were installed using helm with the default parameters or parameters recommended in the documentation
- No optimisations were made to any of the products
- The same features were enabled and tested:
- Enforced mTLS
- Exposing services to the Internet using the documentation recommended method
As part of this task, we also created Operational Manual Updates document. This document explains the important components of each product, including the installation instructions. Product installations were performed using commands from the Operational Manual Updates document, which were scripted into a bash script to simplify the process.
Test Application
To test a service mesh, an application with multiple microservices is necessary. For this reason, we have decided to use the Istio Bookinfo app. The original templates were wrapped into a helm chart and installed on all our environments using Flux which runs in LWDE.
Test Approach
This section explains our test approach. When running the tests initially, we faced numerous challenges, resolved before running the final comparison tests and capturing the results. Consequently, this iterative approach improved the reliability and accuracy of the data captured. I have included the details of these challenges and the steps to resolve them in the Iterate and Improve subsection.
Our test approach is similar to other tests available on the Internet. We generated the load in the test applications of the different environments, comparing the latency, QPS, time, etc. We used an oha load testing tool to generate the load onto the test application. There were two types of traffic: internal and external, or, simply, running oha against Service IP and Ingress IP.
Refer to the below diagrams to see the difference between Internal and External Testing:
Internal Load Testing Figure - Load testing internal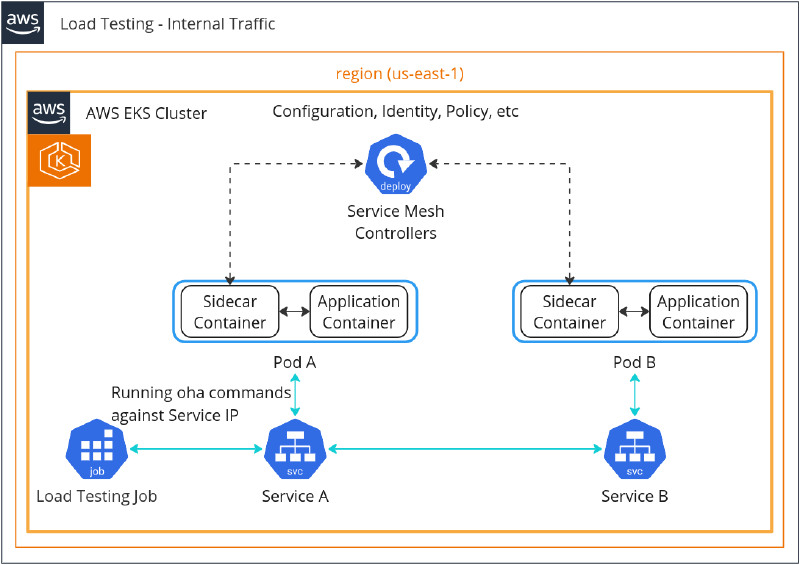
External Load Testing Figure - Load testing external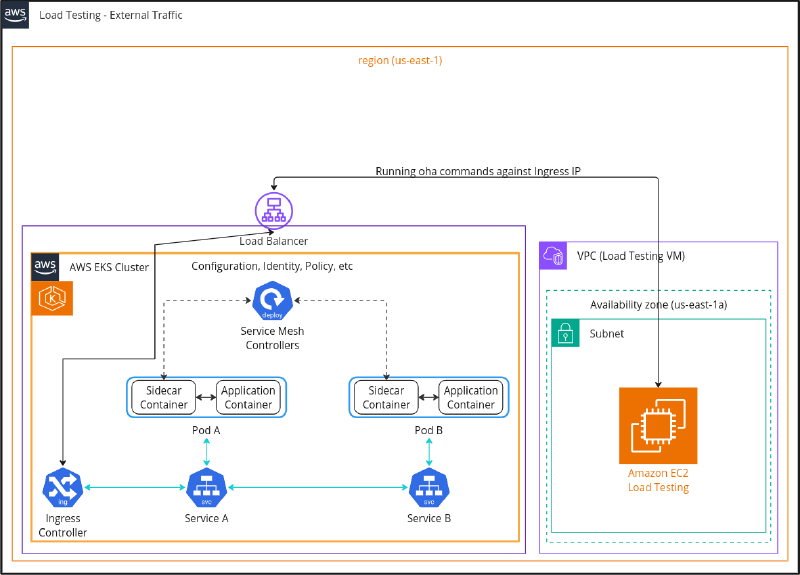
Note: A service mesh with sidecars used as an example here
Below you can see the oha command used to generate the load onto test application:
oha $URL -c $CONCURRENT_CONNECTIONS -n $REQUESTS --disable-keepalive --disable-compression --insecure --ipv4 --no-tui
$URL is a DNS name of the service, $CONCURRENT_CONNECTIONS is a number of concurrent connections, $REQUESTS is a number of requests to send.
Tests were performed using 32, 64 and 128 concurrent connections, it allows us to see the difference between the results keeping the iteration number low.
We set 300,000 requests to send, it allows us to run tests for more than 30 minutes and see more statistically correct information (Refer to improvement I002 for details as to why we did this)
Additionally, to see the full picture, we captured the resource usage of components that were involved in tests, they are included in our Detailed Test Report.
Iterate and Improve
In this section, we will be discussing how we have iterated and improved our testing as part of this process. Since we anticipated that we would need to run multiple iterations of tests, we adopted an iterative approach, analysing the results and making improvements to ensure reliable real-world results. You can find the details of our improvements and failures below:
Improvement - I001: Duration of tests
Details: The first iteration of tests included running oha commands with limited QPS for 3 minutes. We realised that 3 minutes it’s not enough because we have to include cloud faults, which can be noticed on small timeframes but are recovered on bigger timeframes, so the duration of tests was increased up to 30 minutes.
Result: Test output takes into account transient network issues.
Improvement - I002: Replace QPS with the number of requests
Details: We removed the QPS limitation from the oha command. Although limiting QPS is a reliable choice, it requires more iterations of tests and provides more lab results rather than real-world results. Therefore, we decided to use an unlimited number of QPS to test the maximum performance of each product without overheating it. We changed -q argument in oha command to -n, which sets the number of requests that should be delivered.
Result: New approach loads our environment correctly, without slamming products or overheating them.
Improvement - I003: Warm Up
Details: During the first iteration of tests we noticed that the first test took longer to complete than all subsequent tests. It turned out, that after each test application restart we need to do a small warm-up of it. As a result, we added a few more tests, results of which are not included in the report.
Result: Results are more consistent.
Improvement - I004: Test Applications
Details: We simplified test applications setup. We removed podinfo test application, as it doesn’t show the service mesh use case, because there is only one microservice. We also removed HA mode of bookinfo test applications, as it requires more iterations of tests and doesn’t show the significant difference in the results.
Result: Test run takes less time.
Improvement - I005: Availability zone
Details: During the first iteration of tests we noticed that the results across environments are different even when the service mesh disabled, so we decided to minimise the difference between the environments and deploy all nodes in the same availability zone.
Result: Results become slightly better, but the difference is still big.
Improvement - I006: Region
Details: After the second iteration of tests, when the results across environments are different even when the service mesh disabled, we decided to move from eu-west-2 to us-east-1 as it’s the biggest and oldest AWS region.
Result: The difference in results between the environments ranges from 3% to 5%.
Improvement - I007: Run tests concurrently
Details: To minimise the difference between the environments we decided to run tests concurrently.
Result: Overall network load is consistent across all environments.
Failure - F001: VM (External Communication) test on 128 concurrent connections failed for two environments
Details: Tests for Cilium and Baseline have failed due to a memory leak in the bookinfo app, that caused pod recreation.
Сonsequence: It is not possible to include these results in the test report as they are not reliable.
Performance Test Results
This section summarises the performance of each of the three products. You can find more detailed results, where we compare performance and additional parameters, in our Detailed Test Report on GitHub.
Internal Communications Test Results Diagram: Figure - Internal Communications Test Results Diagram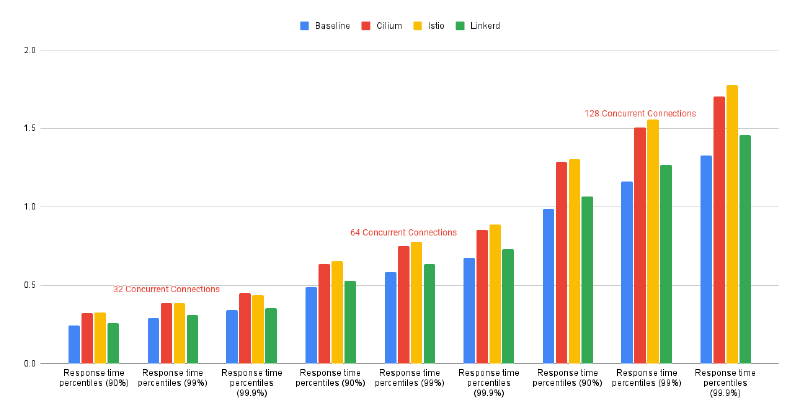
External Communications Test Results Diagram: Figure - External Communications Test Results Diagram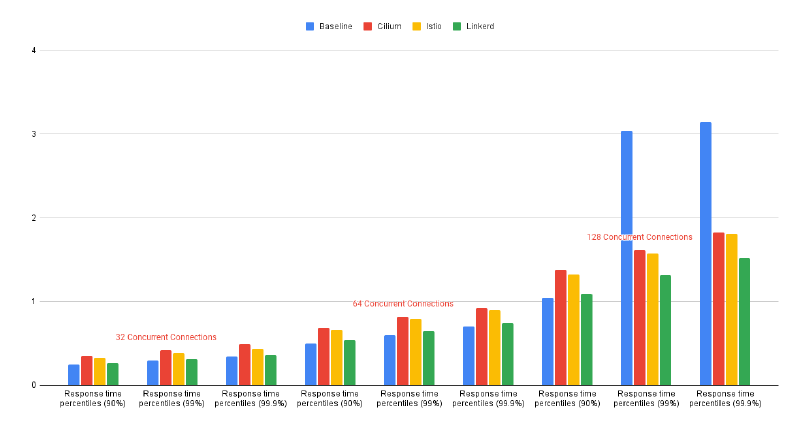
Note: For an explanation of the outlying test results for Cilium and Baseline in the External Communications Test on 128 concurrent connections, refer to F001 in the Iterate and Improve section
Linkerd
Our results show Linkerd is the fastest and most efficient mesh among all those tested, although it is slower than the baseline by 5-10%. Linkerd’s sidecars’ resource utilisation is low, but when it comes to ingress traffic, its resource usage is highly reliant on third-party ingress controllers. As a result, other meshes with their own controllers demonstrated better resource usage.
Cilium
Cilium’s performance is slower than Linkerd’s but performs comparatively to Istio. In comparison to the baseline Cilium’s performance is slower by 20-30% for Internal communications and 30-40% for External communications. The resource utilisation of Cilium’s daemon sets is low; however, other meshes have demonstrated better results in terms of QPS.
Istio
Istio is slower than Linkerd but performs almost as well as Cilium. It is slower than the baseline by 25-35%. The resource utilisation of Istio’s sidecars is higher than Linkerd’s, but the performance is lower. Istio’s Ingress Controller showed the best resource usage among the three tested meshes.
Service Mesh Summary
To summarise, Linkerd is the fastest service mesh among the chosen products tested. If Linkerd was not a suitable product, and you were choosing between Istio and Cillium, your decision would differ depending on your requirements. Istio provides higher QPS and lower latency on low connections, while Cilium performs better on higher connections and internal communications.
If performance is not the primary factor in your decision-making, check out our Detailed Test Report, which captures additional parameters such as ease of deployment, maintainability, operational impact, compliance, and more.
This blog is part of our Service Mesh series, we recommend reading the rest of the posts in the series:
- Service Meshes Decoded: Istio vs Linkerd vs Cilium
- Service Meshes Decoded: Is Istio Ambient worth it?