
VPA production deployment: Avoiding pitfalls for safe and effective scaling
Master systematic VPA rollout strategies, workload coordination, and monitoring approaches for reliable production scaling.
Written by:
Published on:
Oct 7, 2025Last updated on:
Mar 23, 2026This blog is part of our Vertical Pod Autoscaling series, we recommend reading the rest of the posts in the series:
- Understanding Kubernetes VPA: Why manual resource allocation is costing you thousands
- VPA component deep dive: How Kubernetes Vertical Pod Autoscaler works
- VPA production deployment: Avoiding pitfalls for safe and effective scaling
- Advanced VPA implementation: Production patterns, ecosystem tools, and real-world configuration
What separates successful VPA implementations from those abandoned after causing service disruptions? The difference rarely comes down to technical configuration complexity. Instead, it is about approaching VPA as a systematic capability rather than a feature rollout, building operational understanding whilst minimising risk through careful observation and gradual expansion.
Most VPA failures happen not because the technology fails, but because teams rush into automated scaling without establishing the foundational practices needed for sustainable adoption. This creates operational chaos that makes it difficult to understand VPA behaviour, validate recommendations, or troubleshoot issues when they inevitably arise.
Please note: The examples in this blog assume VPA installation via the Fairwinds Helm chart. If you installed VPA using the official installation scripts from the kubernetes/autoscaler repository, the pod labels will differ. For official installations, use -l app=vpa-* instead of the Fairwinds chart labels shown in these examples.
How do you plan a systematic VPA rollout?
Production VPA deployment succeeds when you treat it as a programme of work (rather than a point-in-time implementation). This systematic approach builds confidence through observable results whilst avoiding the common pitfalls that emerge when automated resource management meets complex production workloads.
Phase-based rollout
The most effective VPA adoption follows a structured progression that allows teams to validate effectiveness at each stage whilst building the operational expertise needed for broader implementation. Teams will typically succeed when they resist the urge to enable automation immediately and instead build understanding through observation.
Observation phase establishes baseline understanding through VPA recommendations without automatic implementation. This phase typically lasts one to two weeks depending on application complexity, though teams could extend this for mission-critical applications where understanding consumption patterns is essential before enabling any automation:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: initial-observation-vpa
namespace: development
labels:
deployment-phase: "observation"
review-date: "2025-10-10"
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
updatePolicy:
updateMode: "Off"
resourcePolicy:
containerPolicies:
- containerName: web-container
minAllowed:
cpu: 100m
memory: 128Mi
maxAllowed:
cpu: 2000m
memory: 4Gi
controlledResources: ["cpu", "memory"]
During this phase, you will want to monitor recommendation stability using kubectl describe vpa initial-observation-vpa daily. The goal is understanding how VPA analyses your specific applications whilst identifying workloads where suggestions align with your operational understanding versus those where recommendations seem inappropriate or unstable. What this means is that you are building confidence in VPA’s analytical approach before committing to any automation.
Testing phase moves to controlled automatic scaling in non-production environments that mirror production characteristics. This provides safe environments for understanding how VPA changes affect application performance without risking production stability:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: testing-phase-vpa
namespace: staging
labels:
deployment-phase: "testing"
monitoring-enabled: "true"
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
updatePolicy:
updateMode: "InPlaceOrRecreate"
resourcePolicy:
containerPolicies:
- containerName: web-container
minAllowed:
cpu: 200m
memory: 256Mi
maxAllowed:
cpu: 1500m
memory: 3Gi
controlledResources: ["cpu", "memory"]
The testing phase should include performance validation, monitoring pattern establishment, and operational scenario planning. Because of this systematic approach, teams build understanding of how VPA behaves under different conditions whilst establishing the confidence needed for production deployment.
Which workloads should you target first?
Understanding workload selection criteria helps you choose applications that maximise your chances of successful VPA adoption whilst providing meaningful business value. After all, demonstrating early wins builds organisational confidence in the platform.
Long-running services with predictable patterns represent the best starting point for VPA adoption. Background processing services, API endpoints with consistent traffic patterns, and monitoring systems often exhibit the resource consumption stability that makes VPA analysis reliable. What this means is that VPA can generate accurate recommendations based on stable consumption data rather than trying to optimise highly variable workloads.
Development and staging environments offer excellent opportunities for initial VPA implementation because they typically have more flexible availability requirements whilst supporting diverse workloads that change frequently. These environments often waste significant resources through conservative allocation patterns inherited from production configurations, making them ideal candidates for immediate cost savings whilst building operational expertise.
Applications with clear resource inefficiencies provide compelling demonstration cases where VPA can deliver obvious improvements. Services that consistently use significantly less CPU / memory than their current allocation particularly benefit from VPA optimisation. Dramatic improvements may be seen with memory-intensive applications like databases or JVM services that have conservative heap allocations.
However, certain workloads should be avoided during initial deployment to prevent early adoption challenges that could undermine team confidence in VPA capabilities.
When does ‘InPlaceOrRecreate’ mode work?
InPlaceOrRecreate mode represents the production-ready approach to VPA automation, but understanding when it actually works versus when it falls back to pod recreation is crucial for setting appropriate expectations. The reality is more nuanced than marketing materials suggest.
What scenarios enable in-place updates?
Successful in-place scenarios include CPU increases that do not require container restart, memory increases when sufficient node capacity exists and the container runtime supports resize operations, and resource adjustments that stay within the node’s available resources.
Generally, in-place updates work best for CPU increases and moderate memory increases. While it is possible to handle most CPU adjustments without pod recreation, memory changes have more constraints because of container runtime limitations and node capacity considerations.
Recreation requirements include memory decreases (most container runtimes require restart to properly release memory), memory increases that exceed current node capacity, CPU changes on older clusters or runtimes without in-place support, and resource adjustments that conflict with other scheduling constraints.
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: production-vpa
namespace: production
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
updatePolicy:
updateMode: "InPlaceOrRecreate"
resourcePolicy:
containerPolicies:
- containerName: web-container
minAllowed:
cpu: 200m
memory: 512Mi
maxAllowed:
cpu: 2000m # Conservative to favour in-place updates
memory: 4Gi # Consider node capacity constraints
controlledResources: ["cpu", "memory"]
Production Pitfalls and Mitigation Strategies
Availability planning mistakes occur when teams assume all updates will be in-place and configure insufficient replica counts or Pod Disruption Budgets for the recreation scenarios that inevitably happen. Even with in-place support, you still need to plan for pod recreation during memory decreases, node capacity constraints, or runtime limitations.
Resource boundary issues emerge when VPA recommendations exceed node capacity, causing repeated recreation attempts that can affect service stability. Setting reasonable maximum resource limits that align with your cluster’s node sizes prevents VPA from generating recommendations that consistently require pod recreation due to scheduling constraints.
Application compatibility problems can occur when applications don’t handle resource changes gracefully, even with in-place updates. Some applications cache resource information at startup or make assumptions about available memory that become invalid when resources change dynamically, requiring application-level awareness of resource updates.
Monitoring ‘InPlaceOrRecreate’ behaviour
Understanding update outcomes requires monitoring VPA events to track whether resource changes were applied in-place or required recreation. This visibility helps you understand the real-world behaviour patterns of your VPA implementations:
# Monitor VPA updater logs for in-place vs recreation decisions
kubectl logs -n kube-system -l app.kubernetes.io/component=updater --tail=100 | \
grep -E "(in-place|recreation|fallback)"
# Check VPA events to understand update patterns
kubectl get events --all-namespaces \
--field-selector involvedObject.kind=VerticalPodAutoscaler \
--sort-by='.lastTimestamp' \
-o custom-columns=NAMESPACE:.namespace,NAME:.involvedObject.name,REASON:.reason,MESSAGE:.message
# Monitor VPA update events to understand behaviour patterns
kubectl get events --field-selector involvedObject.kind=VerticalPodAutoscaler \
--all-namespaces --sort-by='.lastTimestamp' | grep -E "(InPlace|Recreate)"
# Track pod restart frequency to identify recreation patterns
kubectl get events --field-selector reason=Killing --all-namespaces \
--sort-by='.lastTimestamp' | grep vpa
Success rate tracking helps you understand how often in-place updates succeed versus fall back to recreation. This information enables better capacity planning and availability configuration. So under the hood, you are building an understanding of which workloads benefit most from in-place updates and which consistently require recreation due to their resource consumption patterns or cluster constraints.
With this in mind, even teams using InPlaceOrRecreate mode need to plan for mixed update behaviour rather than assuming all changes will be non-disruptive. Availability planning mistakes occur when teams assume all updates will be in-place and configure insufficient replica counts or Pod Disruption Budgets for the recreation scenarios that inevitably happen.
Stateful Applications with VPA
Stateful applications present unique challenges for VPA implementation because resource changes can affect data consistency, cluster coordination, and recovery behaviour. Understanding these complexities enables you to implement VPA safely for databases, message brokers, and other persistent services without risking data integrity or operational stability.
What makes database workloads different?
Database resource management requires understanding how CPU / memory changes affect query performance, cache efficiency, and replication coordination. Because of the persistent nature of database workloads, scaling decisions must not interfere with backup schedules, maintenance windows, or cluster health monitoring.
Since VPA doesn’t have built-in awareness of database maintenance windows, one way you can manage database VPA update modes is using CronJobs to coordinate scaling with operational schedules:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: database-vpa
namespace: data
labels:
workload-type: "database"
maintenance-managed: "true"
spec:
targetRef:
apiVersion: apps/v1
kind: StatefulSet
name: postgres-cluster
updatePolicy:
updateMode: "Initial"
resourcePolicy:
containerPolicies:
- containerName: postgres
minAllowed:
cpu: 1000m
memory: 2Gi
maxAllowed:
cpu: 4000m
memory: 16Gi
controlledResources: ["cpu", "memory"]
---
# CronJob to disable VPA updates during maintenance window
apiVersion: batch/v1
kind: CronJob
metadata:
name: database-vpa-maintenance-enable
namespace: data
spec:
schedule: "0 2 * * 0" # 2AM every Sunday
jobTemplate:
spec:
template:
spec:
serviceAccountName: vpa-maintenance-manager
containers:
- name: disable-vpa
image: bitnami/kubectl:latest
command:
- /bin/sh
- -c
- |
kubectl patch vpa database-vpa -n data --type='merge' \
-p='{"spec":{"updatePolicy":{"updateMode":"Off"}}}'
restartPolicy: OnFailure
---
# CronJob to re-enable VPA updates after maintenance window
apiVersion: batch/v1
kind: CronJob
metadata:
name: database-vpa-maintenance-disable
namespace: data
spec:
schedule: "0 4 * * 0" # 4AM every Sunday (2 hour window)
jobTemplate:
spec:
template:
spec:
serviceAccountName: vpa-maintenance-manager
containers:
- name: enable-vpa
image: bitnami/kubectl:latest
command:
- /bin/sh
- -c
- |
kubectl patch vpa database-vpa -n data --type='merge' \
-p='{"spec":{"updatePolicy":{"updateMode":"Initial"}}}'
restartPolicy: OnFailure
Memory allocation considerations become critical for database workloads because memory changes can significantly affect cache performance, query execution, and buffer pool efficiency. Database containers often benefit from VPA memory optimisation, but changes should be coordinated with database-specific monitoring to ensure that memory adjustments improve rather than degrade performance.
This CronJob approach enables you to coordinate VPA updates with database maintenance schedules, ensuring that resource changes happen only during planned maintenance windows when database disruption is acceptable. You can extend this pattern to integrate with backup schedules, replication coordination, or other database-specific operational requirements.
Although aggressive VPA optimisation might interfere with database buffer pools, in practice, coordinated memory scaling during maintenance windows could actually improve performance by right-sizing buffer allocations without disrupting active database operations.
Message brokers and queue management
Message broker coordination involves understanding how resource changes affect throughput, partition management, and consumer group coordination. Because of the distributed nature of message brokers, scaling decisions must not create message delivery disruptions or rebalancing events that could affect downstream applications.
Message brokers like Apache Kafka, RabbitMQ, or Redis are particularly sensitive to memory allocation patterns. Unlike typical web applications that can gracefully handle memory constraints, brokers often maintain large in-memory buffers, connection pools, and message queues that don’t respond well to sudden resource changes.
The primary concern with VPA and message brokers centres on the restart behaviour. When VPA determines that a pod needs more memory, it must restart the pod to apply the new resource limits. For a message broker, this restart can be catastrophic if not handled properly:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: kafka-vpa
namespace: messaging
labels:
workload-type: "message-broker"
scaling-strategy: "observation-first"
spec:
targetRef:
apiVersion: apps/v1
kind: StatefulSet
name: kafka-cluster
updatePolicy:
updateMode: "Off" # Start with recommendations only
resourcePolicy:
containerPolicies:
- containerName: kafka
minAllowed:
cpu: 1000m
memory: 4Gi # Conservative minimum
maxAllowed:
cpu: 6000m
memory: 16Gi
controlledResources: ["memory"] # Focus on memory optimisation
It is recommended to start off with updateMode: "Off" for message brokers. This allows you to observe VPA’s recommendations without automatic restarts, giving you time to understand the scaling patterns before enabling any automation.
Queue persistence and state management considerations include connection state recovery where clients will need to reconnect, causing message delivery delays or temporary unavailability. In-flight messages may need to be reprocessed, and for clustered brokers like Kafka or RabbitMQ clusters, pod restarts affect cluster membership and partition leadership, which can temporarily impact performance.
Performance impact during scaling events creates particular challenges because you’re not just dealing with application startup time, but also managing consumer lag accumulation whilst the broker restarts, producer backpressure during broker unavailability, and partition rebalancing overhead in clustered setups.
To mitigate these issues, configure more aggressive resource requests initially, allowing VPA to scale down rather than up:
# Conservative starting point for broker resources
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafka-cluster
spec:
template:
spec:
containers:
- name: kafka
resources:
requests:
memory: 6Gi # Start higher than typical usage
cpu: 1000m
limits:
memory: 6Gi
cpu: 1000m
This approach means VPA’s first recommendations are usually to reduce resources, which is less disruptive than scaling up from insufficient resources.
Alternative approaches that many teams adopt include using VPA in recommendation mode to inform manual resource adjustments during maintenance windows, focusing on HPA for scaling broker clusters horizontally rather than vertically scaling individual pods, and implementing scheduled scaling that aligns with known traffic patterns.
Because of these considerations, VPA works best with stateless applications that can tolerate restarts. Message brokers, being inherently stateful and restart-sensitive, often benefit more from careful initial resource sizing informed by VPA recommendations rather than automatic VPA scaling.
After all, understanding these stateful application patterns helps you implement VPA optimisation that enhances rather than disrupts critical infrastructure services.
Coordinate VPA with existing autoscaling
Successfully implementing VPA in environments with existing horizontal scaling requires clear responsibility separation and coordination mechanisms. The goal is preventing scaling conflicts whilst maximising the benefits of both approaches to resource optimisation.
How to avoid HPA and VPA conflicts
Metric separation strategies establish clear boundaries between vertical and horizontal scaling decisions through careful selection of triggering conditions and resource responsibilities. What this means is that each scaling approach addresses appropriate scenarios without interfering with the other.
# HPA managing replica scaling based on latency
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: web-app-hpa
namespace: production
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
minReplicas: 3
maxReplicas: 20
metrics:
- type: Pods
pods:
metric:
name: http_request_latency_ms
target:
type: AverageValue
averageValue: "5000"
---
# VPA optimising memory allocation independently
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: web-app-vpa
namespace: production
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
updatePolicy:
updateMode: "InPlaceOrRecreate"
resourcePolicy:
containerPolicies:
- containerName: web-container
minAllowed:
memory: 128Mi
maxAllowed:
memory: 512Mi
controlledResources: ["memory"]
This configuration demonstrates effective coordination where HPA manages replica scaling based on CPU utilisation and throughput metrics whilst VPA optimises memory allocation independently. Because of this approach, you avoid conflicts by using different resource types for scaling decisions whilst maintaining the benefits of both scaling approaches.
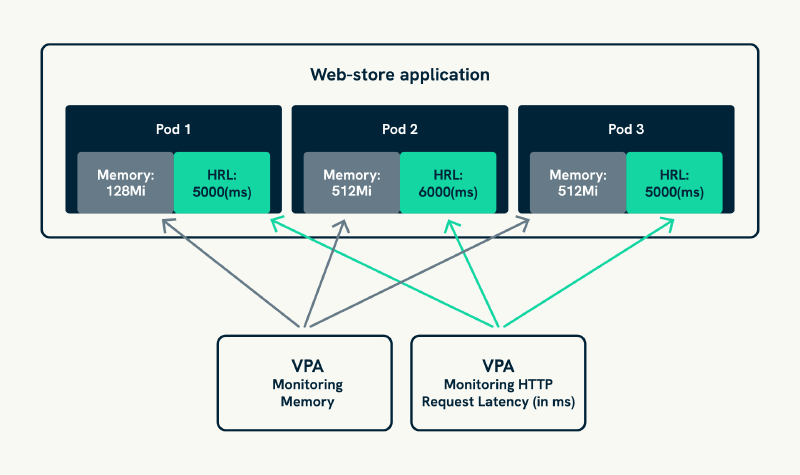
Timing coordination manages the different response frequencies between horizontal and vertical scaling to prevent conflicts whilst ensuring that both scaling approaches can operate effectively. Coordinated timing ensures that VPA changes happen during maintenance windows or low-traffic periods whilst HPA continues providing responsive capacity management during business hours.
Maintain service availability during VPA updates
Maintaining service availability during VPA resource updates requires sophisticated coordination with availability protection mechanisms. This ensures optimisation does not compromise reliability through proper integration with Pod Disruption Budgets and health check coordination.
How does pod disruption budget integration work?
Availability protection ensures that VPA resource changes respect your service reliability requirements through careful coordination with cluster scheduling and deployment strategies:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: web-app-pdb
namespace: production
spec:
minAvailable: 75%
selector:
matchLabels:
app: web-service
---
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: availability-aware-vpa
namespace: production
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
updatePolicy:
updateMode: "InPlaceOrRecreate"
resourcePolicy:
containerPolicies:
- containerName: web-container
minAllowed:
cpu: 200m
memory: 512Mi
maxAllowed:
cpu: 2000m
memory: 4Gi
controlledResources: ["cpu", "memory"]
This pattern demonstrates how VPA coordinates with Pod Disruption Budgets to ensure that resource changes happen only when sufficient service capacity remains available. With this in mind, automated scaling does not cause service outages that could affect customer experience because VPA respects your availability constraints.
Health Check Coordination
Application readiness considerations involve configuring health checks that account for resource change impacts whilst providing adequate time for applications to stabilise after resource adjustments:
apiVersion: apps/v1
kind: Deployment
metadata:
name: health-aware-app
namespace: production
spec:
replicas: 4
template:
spec:
containers:
- name: application
image: java-service:latest
resources:
requests:
cpu: 500m
memory: 1Gi
readinessProbe:
httpGet:
path: /health/ready
port: 8080
initialDelaySeconds: 60 # Accounting for JVM startup
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
livenessProbe:
httpGet:
path: /health/live
port: 8080
initialDelaySeconds: 120 # Extended for resource changes
periodSeconds: 30
timeoutSeconds: 10
failureThreshold: 3
Applications with longer startup times, particularly JVM-based services, require health check configurations that accommodate the additional time needed for applications to stabilise after resource changes. Because of this consideration, VPA optimisation does not trigger unnecessary pod restarts or false availability alerts.
Monitoring VPA Performance & Effectiveness
Implementing comprehensive VPA monitoring provides the visibility needed to validate optimisation effectiveness, troubleshoot issues, and demonstrate business value. The goal is building confidence in VPA decisions through concrete metrics that support continued adoption.
Essential VPA metrics
Recommendation accuracy tracking enables you to understand how well VPA suggestions align with actual application behaviour whilst identifying workloads where recommendations might need adjustment:
# Check recommendation stability over time
kubectl describe vpa <vpa-name> -n <namespace>
# Monitor VPA-related events across the cluster
kubectl get events --field-selector involvedObject.kind=VerticalPodAutoscaler \
--all-namespaces
# Track resource efficiency improvements
kubectl top pods -n <namespace> --containers
Cost impact analysis can help demonstrate the business value of VPA adoption through concrete financial metrics that quantify resource efficiency improvements. Generally, successful implementations can achieve 20% to 40% cost reduction for over-provisioned applications, though results could vary significantly based on initial allocation accuracy and application characteristics.
Troubleshooting common VPA issues
Recommendation instability can often indicates workloads with highly variable resource consumption patterns that might not be suitable for automated optimisation. Alternatively, it can suggest environments where insufficient historical data prevents accurate analysis:
# Check for recommendation fluctuations
kubectl describe vpa <vpa-name> -n <namespace> | grep -A 10 "Target"
# Verify sufficient metrics data availability
kubectl top pods -n <namespace> --containers --sort-by=memory
Update failures can typically result from resource constraints, Pod Disruption Budget conflicts, or node capacity limitations that prevent VPA from implementing recommended changes:
# Check VPA updater logs for issues
kubectl logs -n kube-system -l app.kubernetes.io/component=updater
# Verify cluster resource availability
kubectl describe nodes | grep -A 5 "Allocated resources"
Rather than most VPA issues being configuration-related, but in practice, cluster capacity constraints and workload variability can cause more operational challenges than incorrect VPA settings. Understanding these patterns can help you maintain reliable VPA operation whilst building the operational expertise needed for broader adoption.
Operational reality of production VPA
So under the hood, production VPA deployment succeeds when you approach it systematically rather than rushing to enable automation. The systematic approaches covered here build the confidence and expertise needed for successful VPA implementation at scale, transforming resource allocation from reactive problem-solving into proactive infrastructure optimisation.
What this means is that VPA can become a reliable operational capability, rather than an experimental feature, when you invest time in understanding its behaviour patterns, coordination requirements, and monitoring needs. After all, the most successful VPA deployments are those where teams build operational maturity alongside technical implementation.
Because of this methodical approach, VPA delivers consistent optimisation benefits whilst maintaining operational excellence. However, whilst basic VPA implementation provides significant value, advanced patterns can extend these benefits for complex enterprise environments where standard vertical scaling represents just the beginning of comprehensive resource optimisation strategies.
With this in mind, Part 4 of this series will examine advanced VPA implementation patterns, custom metrics integration, and ecosystem tooling that extends VPA capabilities for enterprise environments where coordination with business objectives and operational workflows becomes essential for delivering strategic infrastructure value.
Frequently Asked Questions
How long should I run VPA in ‘Off’ mode before enabling automation?
For production workloads, we recommend at least one week of observation to capture daily patterns, with two weeks being ideal for applications with weekly usage cycles. Development environments can typically move faster, often within two to three days. Monitor recommendation stability during this period - if recommendations are changing significantly day-to-day, extend the observation period until you see consistent patterns.
What’s the difference between ‘Initial’ and ‘InPlaceOrRecreate’ mode for different use cases?
Initial mode only optimises new pods created through scaling or natural recreation, leaving existing pods unchanged. InPlaceOrRecreate mode actively optimises all pods, using in-place updates when possible or recreation when necessary. Choose Initial for gradual adoption or stateful applications where you want minimal disruption, and InPlaceOrRecreate for comprehensive optimisation when your cluster supports modern VPA features (Kubernetes 1.27+ with VPA 1.2+).
How do you measure the business impact of VPA implementation?
Track quantifiable metrics including cost savings from reduced resource allocation (typically 20% to 40% for over-provisioned applications), operational efficiency gains from automated resource management, and improved resource utilisation ratios. Monitor application performance metrics alongside VPA changes to ensure optimisation improves rather than degrades service quality.
What are the signs that VPA implementation is ready for broader adoption?
Look for successful VPA operation across multiple namespaces with stable recommendations, team confidence in VPA decision-making, established monitoring and troubleshooting procedures, and demonstrable cost savings or performance improvements. Broader adoption works best when basic VPA operation is well-understood and operationally mature.
Additional Resources
- VPA Best Practices Guide
- Kubernetes Pod Disruption Budget Documentation
- HPA and VPA Coordination Patterns
- StatefulSet Resource Management
- VPA Troubleshooting Guide
- Kubernetes Health Check Configuration
This blog is part of our Vertical Pod Autoscaling series, we recommend reading the rest of the posts in the series:
- Understanding Kubernetes VPA: Why manual resource allocation is costing you thousands
- VPA component deep dive: How Kubernetes Vertical Pod Autoscaler works
- VPA production deployment: Avoiding pitfalls for safe and effective scaling
- Advanced VPA implementation: Production patterns, ecosystem tools, and real-world configuration