VPA component deep dive: How Kubernetes Vertical Pod Autoscaler works
Understand the inner workings of VPA’s Recommender, Updater, and Admission Controller to configure reliable resource optimisation.
Written by:
Published on:
Sep 29, 2025Last updated on:
Mar 23, 2026This blog is part of our Vertical Pod Autoscaling series, we recommend reading the rest of the posts in the series:
- Understanding Kubernetes VPA: Why manual resource allocation is costing you thousands
- VPA component deep dive: How Kubernetes Vertical Pod Autoscaler works
- VPA production deployment: Avoiding pitfalls for safe and effective scaling
- Advanced VPA implementation: Production patterns, ecosystem tools, and real-world configuration
What does VPA actually do when it analyses your workloads and recommends resource changes?
Understanding how VPA’s three core components work together transforms what can feel like mysterious scaling decisions into predictable automation that you can configure with confidence. The 2025 evolution of VPA has introduced capabilities like in-place Pod resizing (available in Kubernetes 1.27+ with VPA 1.2+) that fundamentally change how these components coordinate to deliver resource optimisation.
The difference between VPA configurations that deliver consistent results and those that create operational headaches lies in understanding how the Recommender analyses historical data, how the Updater orchestrates resource changes, and how the Admission Controller applies recommendations to new pods whilst respecting your operational constraints.
Please note: The examples in this blog assume VPA installation via the Fairwinds Helm chart. If you installed VPA using the official installation scripts from the kubernetes/autoscaler repository, the pod labels will differ. For official installations, use -l app=vpa-* instead of the Fairwinds chart labels shown in these examples.
How do VPA’s components work together?
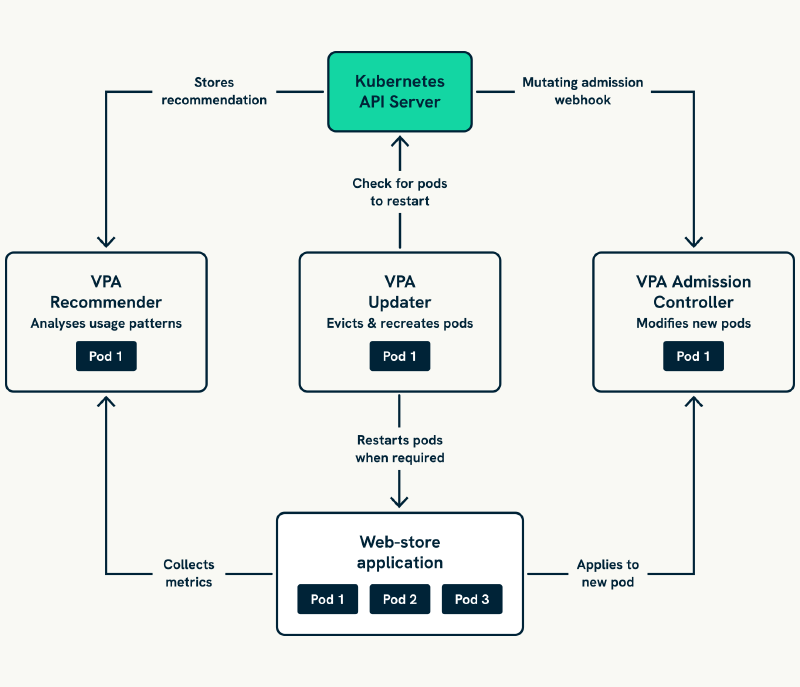
VPA implements automated resource optimisation through three specialised components that divide the complex task of resource management into distinct, coordinated responsibilities. Understanding this architecture helps you configure each component appropriately whilst appreciating how they collaborate to deliver reliable scaling decisions.
Component coordination flow demonstrates how VPA maintains continuous optimisation through systematic phases:
- Data Collection: The Recommender gathers resource consumption metrics from the Kubernetes metrics API, building comprehensive usage profiles for each managed workload
- Analysis: Statistical analysis of historical consumption patterns generates specific CPU and memory allocation recommendations
- Implementation: The Updater evaluates recommendations against current pod configurations, determining when changes warrant action
- Change Orchestration: Resource changes are applied through either in-place updates or graceful pod recreation, respecting availability constraints
- Real-time Optimisation: The Admission Controller ensures new pods benefit from current recommendations during scaling events
This coordinated approach provides reliable resource optimisation that adapts to changing conditions whilst maintaining the operational predictability that production environments require. Each component has a specific role that contributes to the overall optimisation process; understanding these roles enables you to configure VPA effectively for your environment.
VPA Recommender: The analytical engine
The VPA Recommender serves as the intelligence centre that transforms raw resource consumption metrics into actionable scaling recommendations through statistical analysis of historical usage patterns collected from your cluster’s metrics systems.
How does the Recommender process data?
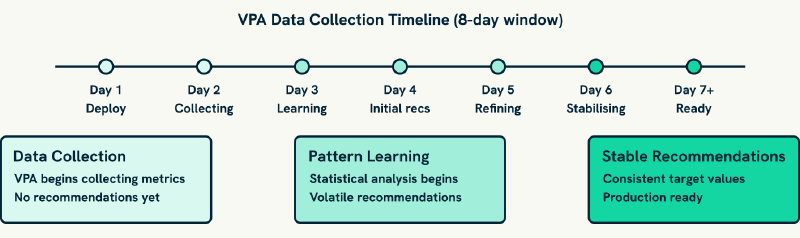
Data collection mechanisms enable the Recommender to gather comprehensive resource consumption information through Kubernetes metrics-server, maintaining detailed consumption statistics across configurable time windows. By default, the Recommender retains 8 days of historical data, which provides sufficient context for identifying usage patterns whilst balancing storage requirements.
What this means is that VPA will need at least 24 to 48 hours of data before generating meaningful recommendations. Applications with weekly usage patterns will often benefit from extending this observation period to capture full operational cycles.
Statistical analysis capabilities process collected metrics using percentile-based calculations rather than simple averages. The Recommender typically uses the 95th percentile for memory recommendations to ensure adequate headroom for applications with occasional memory spikes, whilst using different approaches for CPU recommendations that account for burst patterns and sustained load characteristics.
Recommendation generation produces specific CPU and memory allocation suggestions that include target values, lower bounds, and upper bounds. These recommendations reflect actual application behaviour rather than conservative estimates, enabling more efficient resource allocation that maintains performance whilst reducing waste.
Basic Recommender configuration
Here is a working VPA configuration that demonstrates how the Recommender analyses a web application:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: web-app-vpa
namespace: production
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
updatePolicy:
updateMode: "Off"
resourcePolicy:
containerPolicies:
- containerName: web-container
minAllowed:
cpu: 100m
memory: 128Mi
maxAllowed:
cpu: 2000m
memory: 4Gi
controlledResources: ["cpu", "memory"]
This configuration tells the Recommender to analyse the web-application deployment and generate recommendations within the specified boundaries, but will not automatically apply changes due to the Off update mode. Understanding the Recommender’s analysis process helps you interpret these recommendations and make informed decisions about when to implement them.
You can check the recommendations using:
kubectl describe vpa web-app-vpa -n production
The output includes target recommendations, lower bounds, and upper bounds for both CPU and memory, along with timestamps showing when recommendations were last updated. You may generally find that an application with stable recommendations over several days may indicate it is a good candidate for automated scaling.
VPA Updater: Orchestrates resource changes
The VPA Updater handles the complex orchestration required to implement resource recommendations whilst maintaining service availability through integration with Kubernetes scheduling and pod lifecycle management. Understanding how it makes decisions enables you to choose appropriate update modes and configure VPA for reliable operation.
Understanding VPA update modes
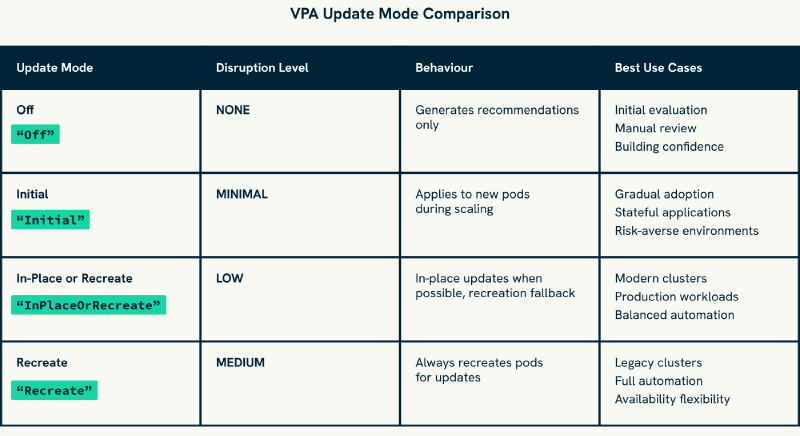
The Updater’s behaviour is controlled through update modes that determine how VPA applies resource recommendations. Each mode represents a different balance between automation benefits and operational control:
How do update modes work in practice?
Off Mode provides the safest starting point for VPA evaluation, generating recommendations without any automated changes. This mode allows you to observe VPA suggestions and build confidence in the system whilst learning how your applications behave under VPA analysis. Most teams start here to validate recommendation quality before enabling any automation.
Initial Mode applies recommendations only when pods are first created, leaving existing running pods unchanged until they are naturally recreated through scaling events or infrastructure maintenance. This approach optimises resource allocation for future pods whilst avoiding disruption to currently running services, making it ideal for gradual VPA adoption.
InPlaceOrRecreate Mode represents the modern approach to VPA automation, attempting to update resources without pod recreation when possible. For Kubernetes clusters version 1.27+ with in-place resizing support, this mode delivers the best balance of automation and minimal disruption. When in-place updates are not possible, it falls back to graceful pod recreation whilst respecting availability constraints.
Recreate Mode provides full automation by automatically applying recommendations through pod eviction and recreation. Whilst this mode causes service disruption during updates, it ensures that all pods eventually receive optimised resource allocations regardless of cluster capabilities or update compatibility.
In-place updates vs pod recreation
Scenarios where in-place updates work include those where CPU increases can be applied without pod restart, and memory increases work when the new allocation fits on the current node and the container runtime supports resize operations. This capability significantly reduces the operational impact of VPA optimisation by enabling resource adjustments without service disruption.
In-place updates may succeed most reliably for:
- CPU increases up to node capacity limits
- Memory increases when sufficient node capacity exists
- Resource adjustments on clusters with modern container runtimes (containerd 1.6+, CRI-O 1.25+)
When recreation is required includes memory decreases (most container runtimes require restart), very large memory increases that exceed node capacity, and containers that do not support in-place updates. The Updater will automatically detect these scenarios and fall back to graceful pod recreation whilst maintaining service availability through coordination with Pod Disruption Budgets.
Understanding these capabilities will help you choose appropriate update modes based on your cluster capabilities and availability requirements, ensuring that VPA optimisation enhances rather than compromises your operational reliability.
VPA Admission Controller: Resource optimisation
The VPA Admission Controller provides immediate resource optimisation for new pod deployments by intercepting pod creation requests and applying current VPA recommendations before pods are scheduled. This ensures that newly created pods start with optimised resource allocations rather than inheriting outdated manual estimates.
How does the Admission Controller work?
Webhook integration enables the Admission Controller to operate through a mutating admission webhook that examines pod creation requests and modifies resource specifications based on current VPA recommendations. This integration happens before pod scheduling, ensuring that resource optimisation is applied immediately when pods are created.
So under the hood, when you scale a deployment or other workload, the Admission Controller intercepts the pod creation and modifies the resource requests to match the VPA’s current recommendations, even though the original deployment YAML might specify different values.
Real-time recommendation application means new pods automatically benefit from current VPA analysis without requiring additional update cycles. When you scale a deployment or pods are recreated for operational reasons, the Admission Controller applies the most recent recommendations, providing immediate resource optimisation that reflects current application behaviour patterns.
This coordination between the Admission Controller and VPA recommendations ensures that scaling events immediately benefit from resource optimisation, which becomes particularly valuable during traffic spikes or rolling deployments.
Resource Policies: What controls do you have?
Resource policies provide the control mechanisms that enable teams to implement VPA optimisation within operational boundaries whilst preventing automatic scaling decisions from violating resource governance requirements or operational constraints.
Container-specific policy controls
Individual container management enables different policies for different containers within the same pod, providing granular control that is particularly valuable for multi-container architectures:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: web-store
namespace: production
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
updatePolicy:
updateMode: "InPlaceOrRecreate"
resourcePolicy:
containerPolicies:
- containerName: web-container
minAllowed:
cpu: 200m
memory: 256Mi
maxAllowed:
cpu: 2000m
memory: 4Gi
controlledResources: ["cpu", "memory"]
- containerName: logging-sidecar
minAllowed:
cpu: 50m
memory: 64Mi
maxAllowed:
cpu: 200m
memory: 256Mi
controlledResources: ["cpu", "memory"]
mode: "Off"
This configuration optimises the main application container whilst keeping the logging sidecar’s resources stable, demonstrating how you can apply different optimisation strategies to different containers based on their operational requirements.
Controlling which resources VPA manages
Resource-specific controls enable precise management of which resources VPA should optimise:
# CPU-only optimisation for compute-intensive applications
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: cpu-only-vpa
namespace: production
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: cpu-intensive-app
resourcePolicy:
containerPolicies:
- containerName: cpu-app
minAllowed:
cpu: 500m
maxAllowed:
cpu: 4000m
controlledResources: ["cpu"]
Memory-only optimisation works well for data processing applications where you want to optimise memory allocation whilst maintaining consistent CPU allocation:
# Memory-only optimisation for data processing workloads
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: memory-only-vpa
namespace: production
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: data-processor
resourcePolicy:
containerPolicies:
- containerName: processor
minAllowed:
memory: 1Gi
maxAllowed:
memory: 16Gi
controlledResources: ["memory"]
These examples demonstrate how resource policies enable you to implement optimisation strategies that align with your application characteristics whilst maintaining operational control over resource allocation decisions.
How do you monitor VPA health?
Understanding how VPA components are performing helps you validate effectiveness and troubleshoot issues when they arise. Basic monitoring provides the visibility needed for confident VPA operation.
Basic VPA health checks
# Check VPA component pods are running
kubectl get pods -n kube-system -l app.kubernetes.io/name=vpa
# Verify VPA resources across the cluster
kubectl get vpa --all-namespaces
# Get detailed status for specific VPA
kubectl describe vpa <vpa-name> -n <namespace>
# Check recent VPA-related events
kubectl get events --field-selector involvedObject.kind=VerticalPodAutoscaler \
--all-namespaces
How do you interpret VPA status?
When you describe a VPA resource, you will see output like this:
Status:
Conditions:
Status: "True"
Type: RecommendationProvided
Recommendation:
Container Recommendations:
Container Name: web-server
Lower Bound:
Cpu: 100m
Memory: 256Mi
Target:
Cpu: 280m
Memory: 650Mi
Upper Bound:
Cpu: 500m
Memory: 1Gi
Target values represent VPA’s recommended allocation based on observed usage patterns. Lower bounds indicate minimum resources needed for basic operation, whilst upper bounds suggest maximum reasonable allocation based on observed peaks. Understanding these values helps you evaluate recommendation quality and make informed decisions about implementation.
Large differences between lower and upper bounds may often indicate applications with highly variable resource consumption that might benefit from careful review before enabling automation.
VPA Common issues and solutions
The sophisticated coordination between VPA’s Recommender, Updater, and Admission Controller provides reliable resource optimisation when configured appropriately for your environment. Understanding how these components work enables you to implement VPA solutions that deliver consistent optimisation benefits whilst maintaining operational control.
Quick diagnosis patterns
Recommendation instability often indicates workloads with highly variable resource consumption patterns that might not be suitable for automated optimisation, or environments where insufficient historical data prevents accurate analysis. Generally, we recommend at least one week of observation before enabling automation.
Update failures typically result from Pod Disruption Budget conflicts or resource quota limitations. Check that your PDB configuration allows for pod updates and that namespace resource quotas can accommodate VPA recommendations.
Performance impacts can occur when applications do not handle resource changes gracefully, even with in-place updates. Some applications cache resource information at startup or make assumptions about available memory that become invalid when resources change dynamically.
Monitoring update success
# Monitor VPA update events to understand behaviour patterns
kubectl get events --field-selector involvedObject.kind=VerticalPodAutoscaler \
--all-namespaces --sort-by='.lastTimestamp' | grep -E "(InPlace|Recreate)"
# Check recent VPA updater logs for decision reasoning
kubectl logs -n kube-system -l app.kubernetes.io/name=vpa --tail=100 | \
grep -E "(in-place|recreation|fallback)"
# Track pod restart frequency to identify recreation patterns
kubectl get events --field-selector reason=Killing --all-namespaces \
--sort-by='.lastTimestamp' | grep vpa
This foundation will prepare you for Part 3 of this series, where we will explore production deployment strategies that ensure VPA delivers reliable results whilst avoiding operational pitfalls. We will cover systematic rollout approaches, workload-specific considerations, and the coordination patterns that enable successful VPA adoption at scale.
Frequently Asked Questions
How long should I run VPA in ‘Off’ mode before enabling automation?
For production workloads, we recommend at least one week of observation to capture daily patterns, with two weeks being ideal for applications with weekly usage cycles. Development environments can typically move faster, often within 2 to 3 days. Monitor recommendation stability during this period; if recommendations are changing significantly day-to-day, extend the observation period until you see consistent patterns.
What is the difference between ‘Initial’ and ‘InPlaceOrRecreate’ mode for my use case?
Initial mode only optimises new pods created through scaling or natural recreation, leaving existing pods unchanged. InPlaceOrRecreate mode actively optimises all pods, using in-place updates when possible or recreation when necessary. Choose Initial for gradual adoption or stateful applications where you want minimal disruption, and InPlaceOrRecreate for comprehensive optimisation when your cluster supports modern VPA features.
Can I control which containers in a multi-container pod get optimised by VPA?
Yes, resource policies allow per-container control. You can set different modes for each container; for example, optimising your main application container whilst keeping sidecar containers stable by setting their mode to Off. This granular control is particularly valuable for service mesh architectures where you want different optimisation strategies for application containers versus proxy sidecars.
What does it mean when VPA shows different target, lower bound, and upper bound values?
The target represents VPA’s recommended allocation based on typical usage patterns. Lower bound indicates the minimum resources needed for basic operation, whilst upper bound suggests maximum reasonable allocation based on observed usage peaks. If these values are very different, it suggests your application has variable resource consumption patterns that might benefit from careful review before enabling automation.
How do I know if my cluster supports in-place Pod resizing for VPA?
In-place Pod resizing requires Kubernetes 1.27+ with the InPlacePodVerticalScaling feature gate enabled (it is enabled by default in 1.33+) and VPA 1.2+. You can check your cluster’s support by looking at VPA events after enabling InPlaceOrRecreate mode; successful in-place updates will show events like “Successfully updated resources in-place” whilst fallbacks will show “Falling back to recreation”.
Additional Resources
- VPA API Reference Documentation
- VPA Configuration Examples
- Kubernetes Resource Management Concepts
- Kubernetes 1.27 Release Notes - In-Place Pod Resizing
This blog is part of our Vertical Pod Autoscaling series, we recommend reading the rest of the posts in the series:
- Understanding Kubernetes VPA: Why manual resource allocation is costing you thousands
- VPA component deep dive: How Kubernetes Vertical Pod Autoscaler works
- VPA production deployment: Avoiding pitfalls for safe and effective scaling
- Advanced VPA implementation: Production patterns, ecosystem tools, and real-world configuration