Understanding Kubernetes VPA: Why manual resource allocation is costing you thousands
Learn why Kubernetes Vertical Pod Autoscaler has become essential for modern workload optimisation and cost control.
Written by:
Published on:
Last updated on:
This blog is part of our Vertical Pod Autoscaling series, we recommend reading the rest of the posts in the series:
- Understanding Kubernetes VPA: Why manual resource allocation is costing you thousands
- VPA component deep dive: How Kubernetes Vertical Pod Autoscaler works
- VPA production deployment: Avoiding pitfalls for safe and effective scaling
- Advanced VPA implementation: Production patterns, ecosystem tools, and real-world configuration
Introduction
The typical Kubernetes deployment wastes between 40% to 60% of allocated resources through conservative over-provisioning, translating to thousands of pounds in unnecessary cloud spending each month. Yet despite running applications that consume far less CPU and memory than their resource requests suggest, teams continue relying on educated guesswork for resource allocation because the alternatives have historically been worse than the problem they were meant to solve.
Kubernetes Vertical Pod Autoscaler (VPA) started as an experimental scaling component thathas evolved into a production-ready solution that addresses these fundamental resource allocation challenges through data-driven automation that adapts to actual application consumption patterns rather than relying on static estimates.
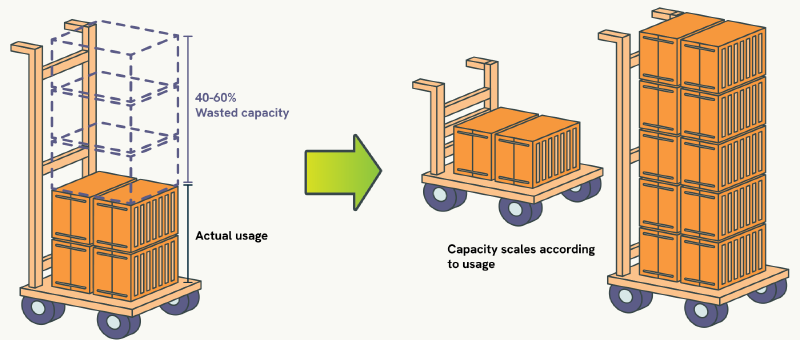
The resource allocation problem
This resource waste is not just an abstract efficiency concern; it creates operational pain that compounds daily across engineering teams. Manual resource sizing creates a cascade of problems that grow more expensive and complex as your Kubernetes deployments scale beyond what any individual can mentally track and optimise.
What form could vertical pod autoscaling take in theory? The ideal solution would automatically analyse actual resource consumption patterns and adjust allocations based on real application behaviour rather than conservative estimates. However, the operational reality has been that early autoscaling solutions often caused more problems than they solved, leaving teams to rely on manual allocation strategies that prioritise safety over efficiency.
Why manual resource management doesn’t scale
The 2AM memory alert scenario can be a familiar nightmare: you have been woken up three times this month because a critical service ran out of memory during peak traffic. The knee-jerk response is to double the memory allocation “just to be safe”, which works until you realise you are now paying for 8Gi of memory for an application that typically uses 1.2Gi during normal operations.
The quarterly capacity planning nightmare forces teams into meetings where you are trying to predict resource requirements for the next three months based on business projections that change weekly. You end up over-provisioning “because it is better to be safe than sorry”, whilst the finance team questions why the cloud bill keeps growing faster than actual usage metrics.
The deployment inheritance problem perpetuates these conservative estimates as new services inherit resource allocations from similar applications, carrying forward safety margins that may have been wrong in the first place. Microservices architectures now have 200+ services, each padded with inherited estimates that compound into massive cluster over-provisioning.
The performance versus cost dilemma creates a ratcheting effect where resource allocations only increase, never optimise. When applications perform poorly, the easiest solution is to throw more resources at them. When costs become a concern, teams are reluctant to reduce allocations because nobody wants to be responsible for performance degradation.
These individual incidents might seem manageable in isolation, but they reveal a deeper systemic issue with how Kubernetes handles resource allocation that affects every cluster at scale.
Financial reality of resource waste
Team capacity limitations mean that systematic resource optimisation becomes impossible as application portfolios grow beyond what humans can reasonably track. Whilst teams might carefully tune resources for their most critical services, the majority of workloads end up with conservative defaults that nobody has time to revisit or validate against actual consumption patterns.
Measurement gaps make it difficult to understand whether applications are actually using their allocated resources. Standard monitoring shows what pods are requesting, but correlating that with actual consumption patterns across hundreds of services becomes a data analysis project that never gets prioritised against feature development work.
Change resistance develops because modifying resource allocations feels risky without comprehensive data about usage patterns. Teams become reluctant to optimise resources because the potential for performance impact outweighs the perceived benefits of cost savings, especially when budget pressure has not reached crisis levels.
The financial impact compounds quickly in production environments where hundreds of applications collectively waste significant resources through systematic over-allocation. A typical enterprise Kubernetes deployment may waste £10K to £50K monthly through conservative resource allocation patterns that seemed reasonable for individual services, but create substantial inefficiency at scale.
After all, understanding why Kubernetes makes resource management so challenging in the first place is essential before we can examine effective solutions.
Why is Kubernetes resource management so complex?
The challenge is not just about setting numbers in YAML files; it is about making accurate predictions in a system where resource decisions have cascading effects on scheduling, performance, and cost. Kubernetes resource management system was designed for predictability and isolation, but these same design principles create the complexity that makes manual allocation so problematic.
Kubernetes resource requests and limits
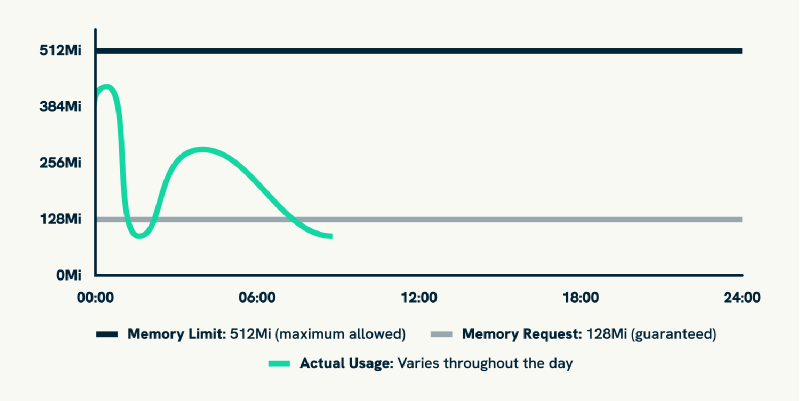
Resource requests and limits form the foundation of Kubernetes resource management, but they require making two separate predictions about application behaviour. Resource requests specify the minimum CPU and memory that Kubernetes guarantees for a container, directly affecting pod scheduling decisions. Resource limits define the maximum resources a container can consume, acting as a ceiling to prevent runaway processes from affecting other workloads.
The scheduling impact of resource requests creates the first layer of complexity because Kubernetes uses these values to determine pod placement across nodes. If you request 1 CPU and 2Gi of memory, Kubernetes will only schedule the pod on nodes with sufficient available capacity, regardless of whether the application actually uses those resources. This means over-estimating requests does not just waste money, it can prevent pods from being scheduled when cluster capacity becomes constrained.
Quality of Service (QoS) classes emerge from the relationship between requests and limits, adding another dimension to resource allocation decisions. Pods with requests equal to limits receive “Guaranteed” QoS, those with requests but no limits get “Burstable” QoS, and pods without requests receive “BestEffort” QoS. These classes affect how Kubernetes handles resource pressure and pod eviction during capacity constraints, meaning resource allocation decisions also determine application survival priority during cluster stress.
The allocation dilemma becomes clear when you realise that setting appropriate requests and limits requires predicting application behaviour under various conditions that might not have been experienced yet. Set requests too low and pods might be scheduled on overcommitted nodes, leading to performance issues. Set them too high and you waste cluster capacity whilst potentially preventing other pods from being scheduled.
So under the hood, this complexity creates the operational challenges that make manual resource allocation such a persistent problem across Kubernetes environments.
How does Kubernetes VPA solve these problems?
Rather than asking teams to predict resource requirements, Kubernetes Vertical Pod Autoscaler flips the entire approach by observing actual consumption patterns and making data-driven recommendations based on real application behaviour. This transforms resource allocation from a prediction problem into an analysis problem, which computers happen to be much better at solving than humans.
VPA replaces guesswork with statistical analysis
Automated resource analysis enables VPA to process millions of resource consumption data points to identify usage patterns, detect trends over time, and generate recommendations that account for application-specific behaviour rather than applying generic sizing assumptions across different workload types. Instead of asking teams to predict how much memory a JVM application will need under various load conditions, VPA observes actual memory consumption across weeks of operation and calculates statistically appropriate allocation values.
Data-driven recommendations replace educated guesswork with statistical analysis of actual consumption patterns. Instead of setting memory requests based on “what seems reasonable”, VPA analyses weeks of actual usage data to determine optimal allocation that balances efficiency with reliability, accounting for variance in consumption and providing appropriate safety margins based on observed behaviour rather than conservative assumptions.
Implementation flexibility allows teams to apply VPA recommendations through multiple approaches, from manual review and implementation to fully automated resource adjustments, enabling gradual adoption that builds operational confidence. This means you can start by observing VPA recommendations to validate their accuracy before enabling any automation, eliminating the risk of unexpected changes whilst building trust in the system.
With this in mind, understanding VPA’s approach helps clarify how it fits within the broader Kubernetes scaling ecosystem, where different types of scaling address different operational challenges.
VPA in the Kubernetes scaling ecosystem
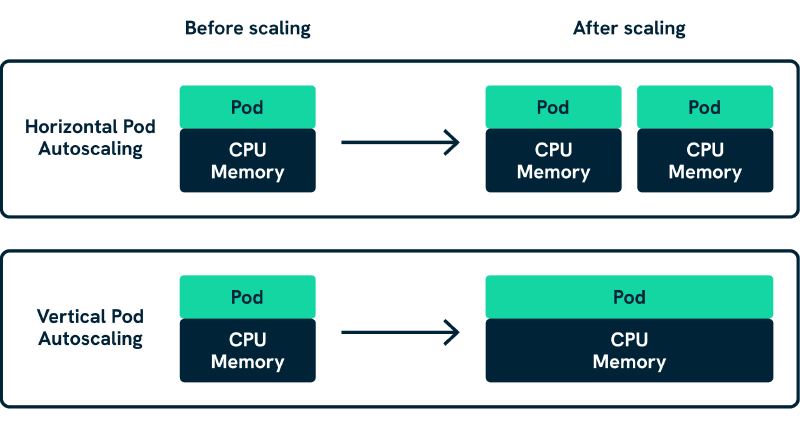
Vertical Pod Autoscaler (VPA) optimises resource allocation for individual pods by adjusting CPU and memory requests based on actual usage patterns. VPA is ideal for workloads with predictable resource consumption patterns where teams want to eliminate waste whilst maintaining consistent performance, particularly for long-running services where resource efficiency directly impacts operational costs.
Horizontal Pod Autoscaler (HPA) manages the number of pod replicas based on observed metrics like CPU utilisation, memory usage, or custom metrics. HPA excels at handling variable load patterns where adding more instances improves performance, such as web applications experiencing traffic spikes or API services with fluctuating request volumes that require capacity scaling rather than resource optimisation.
KEDA (Kubernetes Event Driven Autoscaler) extends horizontal scaling capabilities to support event-driven architectures by scaling workloads based on external metrics from message queues, databases, cloud services, and other event sources. KEDA enables sophisticated scaling scenarios like scaling to zero when no events are present, making it particularly valuable for batch processing, serverless workloads, and applications that respond to external triggers rather than traditional HTTP traffic patterns.
Kubernetes Cluster Autoscaler manages the underlying node infrastructure by adding or removing nodes based on pod scheduling requirements and resource availability. It works at the infrastructure layer to ensure clusters have sufficient capacity to support both vertical and horizontal scaling decisions made by VPA and HPA.
These approaches are complementary rather than competing technologies. A well-designed scaling strategy often combines multiple approaches: VPA ensures optimal resource allocation per pod, HPA manages replica scaling based on demand, KEDA handles event-driven scaling scenarios, and Cluster Autoscaler provides the underlying infrastructure capacity to support all scaling approaches without manual intervention.
Important Note: You cannot use VPA with HPA when both target the same resource metrics (CPU / memory) as this can cause scaling conflicts and unpredictable behaviour.
What this means is that the question becomes: which workloads actually benefit from this approach to resource optimisation?
When does VPA deliver maximum value for your workloads?
Not every application benefits equally from VPA’s statistical approach to resource optimisation. Understanding the workload characteristics that align with VPA’s strengths helps teams prioritise implementation efforts and maximise the cost savings and operational benefits they will achieve from automated resource management.
What makes an ideal VPA candidate?
Stateful applications with predictable patterns represent ideal VPA candidates because they typically run continuously with consistent resource consumption characteristics that enable accurate recommendation generation. Database workloads, message brokers, and data processing applications often exhibit stable resource consumption patterns over time, providing the historical data that VPA needs to generate reliable recommendations without the noise of highly variable workloads.
Memory-intensive workloads particularly benefit from VPA optimisation because memory allocation significantly affects both application performance and infrastructure costs, whilst memory consumption patterns are often more predictable than CPU usage. JVM-based applications, machine learning workloads, and data analytics services frequently consume memory in patterns that are well-suited to VPA analysis, especially when garbage collection and caching behaviours create recognisable usage patterns.
Long-running services with consistent usage benefit tremendously from VPA because they provide the historical data needed for accurate recommendations whilst typically having stable resource consumption patterns that do not require frequent adjustments. Web APIs, background processing services, and monitoring systems often fall into this category, running continuously with consumption patterns that VPA can analyse and optimise effectively.
Development and testing environments provide excellent opportunities for VPA implementation because they typically have more flexible availability requirements whilst supporting diverse workloads that change frequently. Development environments often waste significant resources through conservative allocation patterns inherited from production configurations, making them ideal candidates for aggressive VPA optimisation that delivers immediate cost savings.
When is VPA not the right solution?
Highly variable workloads that experience extreme resource consumption swings might not benefit from VPA’s statistical approach to optimisation. Batch processing jobs with dramatically different resource requirements per job type often need manual tuning rather than automated recommendations, since VPA’s analysis might average across wildly different consumption patterns that do not represent optimal allocation for any specific workload type.
Short-lived applications do not provide sufficient historical data for VPA to generate meaningful recommendations. If applications typically run for minutes rather than hours or days, traditional capacity planning approaches might be more appropriate since VPA needs sustained operation periods to establish reliable consumption patterns.
Applications where pod restart causes significant operational issues might not be suitable for VPA implementations that require pod recreation to apply resource changes, though modern in-place update capabilities address many of these concerns by enabling resource adjustments without service disruption.
Generally, identifying these workload patterns helps teams understand where VPA will be most effective, but implementing VPA successfully requires understanding how its components work together to deliver these optimisation benefits.
How do VPA components work?
Kubernetes VPA implements resource optimisation through three coordinated components that divide the complex task of automated resource management into distinct, manageable responsibilities. Understanding this architecture helps teams configure VPA effectively, troubleshoot issues when they arise, and appreciate how the system maintains reliability whilst making automated changes to running applications.
3 VPA components and their roles
VPA Recommender serves as the analytical engine that processes historical resource consumption data from cluster metrics systems. It maintains detailed consumption statistics across configurable time windows and generates specific CPU and memory allocation recommendations using statistical analysis of actual usage patterns, accounting for variance and providing appropriate safety margins based on observed application behaviour rather than conservative assumptions.
VPA Updater handles the complex orchestration required to implement resource changes whilst maintaining service availability. When VPA operates automatically, the Updater coordinates with Kubernetes scheduling systems to apply resource adjustments, either through modern in-place updates that avoid service disruption or through carefully managed pod recreation that respects availability constraints and Pod Disruption Budget configurations.
VPA Admission Controller provides real-time resource optimisation for new pod deployments by intercepting pod creation requests and applying current VPA recommendations before pods are scheduled. This ensures that newly created pods start with optimised resource allocations, which is particularly valuable during scaling events or rolling deployments.
The components work together in a coordinated cycle where the Recommender analyses metrics and generates recommendations, the Updater evaluates recommendations against current pod configurations and implements necessary changes, and the Admission Controller ensures that new pods benefit from current optimisation insights.

This coordinated approach enables VPA to provide reliable resource optimisation.
A basic VPA Implementation
Understanding VPA concepts is one thing, but seeing how it translates into actual Kubernetes configurations helps bridge the gap between theory and operational reality. Here is a practical example that demonstrates how to configure VPA for a typical web application whilst highlighting the key decisions teams need to make during implementation.
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-app
namespace: web-store
spec:
replicas: 3
selector:
matchLabels:
app: web-app
template:
metadata:
labels:
app: web-app
spec:
containers:
- name: web-container
image: nginx
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi
---
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: web-app-vpa
namespace: web-store
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
updatePolicy:
updateMode: "Off"
resourcePolicy:
containerPolicies:
- containerName: web-container
minAllowed:
cpu: 50m
memory: 64Mi
maxAllowed:
cpu: 1000m
memory: 1Gi
controlledResources: ["cpu", "memory"]
Key configuration decisions
Target workload specification through targetRef connects VPA to the deployment, enabling monitoring and recommendation generation based on actual consumption patterns rather than generic assumptions.
Update mode selection determines implementation approach; Off mode generates recommendations without automation, perfect for building confidence before enabling changes that might affect running services.
Resource policies provide essential guardrails through minimum and maximum boundaries reflecting operational requirements. minAllowed prevents allocations too small for application operation whilst maxAllowed prevents exceeding cost or capacity constraints.
Controlled resources specify exactly which resources VPA should analyse, providing granular control particularly valuable for multi-container pods where you might optimise application containers whilst keeping sidecars stable.
This configuration establishes the foundation for VPA operation, but the real power comes from understanding how different update modes change VPA’s behaviour and impact on running services.
How do VPA Update Modes work?
The way VPA applies its recommendations fundamentally determines how teams experience the system in operation, making update mode selection one of the most important configuration decisions you will make. Each mode represents a different balance between automation benefits and operational control, allowing you to choose the approach that best fits your risk tolerance and operational requirements.
VPA update modes
Off Mode generates recommendations without applying them automatically, making it the perfect starting point for VPA evaluation. This mode allows teams to observe VPA suggestions and build confidence in the system whilst learning how their applications behave under VPA analysis. You can review recommendations using kubectl describe vpa web-app-vpa to see target values, lower bounds, and upper bounds for both CPU and memory, building understanding of VPA’s analytical approach before committing to automation.
Initial Mode applies recommendations only when new pods are created, leaving existing running pods unchanged until they are naturally recreated through scaling events, rolling deployments, or infrastructure maintenance. This approach optimises resource allocation for future pods whilst avoiding disruption to currently running services, making it ideal for gradual VPA adoption where teams want to benefit from optimisation without affecting stable workloads.
Recreate Mode provides full automation by implementing VPA recommendations through pod eviction and recreation. Whilst this mode causes service disruption during updates, it ensures that all pods eventually receive optimised resource allocations. VPA respects Pod Disruption Budgets to maintain service availability during optimisation.
InPlaceOrRecreate Mode will attempt non-disruptive in-place resource updates first, falling back to pod recreation only when necessary. This mode is being developed as part of VPA’s integration with Kubernetes in-place pod resizing capabilities and will provide the best balance of automation and minimal disruption when available.
Auto Mode (deprecated in newer VPA versions) previously provided the same functionality as Recreate mode, but is being phased out in favour of explicit mode selection.
The choice of update mode should reflect operational maturity with VPA, availability requirements, and confidence level with automated resource changes. Most teams start with Off mode to evaluate VPA recommendations, progress to Initial mode for new deployments, and eventually enable Recreate or InPlaceOrRecreate mode for workloads where the operational benefits outweigh the automation risks.
Because of this progression, understanding these modes helps teams plan their VPA adoption journey, but the real confidence comes from knowing that VPA has evolved from an experimental tool into a production-ready platform with enterprise-grade support.
Has VPA really become production-ready?
The transformation of VPA from an experimental Kubernetes component to a production-ready platform represents one of the most significant developments in Kubernetes resource management, addressing the operational concerns that previously prevented widespread adoption whilst adding capabilities that make automated resource optimisation both reliable and beneficial for enterprise workloads.
What modern VPA features enable production adoption?
In-place Pod resizing capabilities are coming to VPA through ongoing development work that will enable resource adjustments without pod recreation for many scenarios that previously required service disruption. This capability eliminates the primary barrier to VPA adoption by enabling resource optimisation without service interruption, particularly valuable for stateful applications and services where pod restart causes operational complexity or performance degradation.
API stability and ecosystem maturity provide confidence in long-term VPA adoption through stable configuration interfaces that will not require frequent migration, comprehensive documentation that supports operational teams, and growing ecosystem support from major cloud providers and Kubernetes management platforms. The maturation of core VPA APIs signals the platform’s readiness for production deployment without concerns about breaking changes or unsupported features.
Enhanced monitoring and observability enable teams to track VPA performance, recommendation accuracy, and optimisation impact through comprehensive metrics and integration with standard Kubernetes monitoring tools. This visibility allows operational teams to validate VPA effectiveness, troubleshoot recommendation issues, and demonstrate the business value of automated resource optimisation through concrete metrics and cost savings analysis.
So after all, what are the next steps for teams considering VPA adoption?
Installing VPA on your Kubernetes cluster
Before you can implement any VPA configurations, you need to actually install the VPA controller components on your cluster. Unlike the Horizontal Pod Autoscaler, which comes built into Kubernetes, VPA is a separate project that must be installed manually. This installation requirement initially surprised us when we first started working with VPA, since the resource optimisation capabilities feel so fundamental to Kubernetes operations.
Prerequisites for VPA installation
Kubernetes cluster requirements include Kubernetes version 1.11 or later with metrics-server installed and functioning properly. The metrics-server provides the resource consumption data that VPA needs to generate recommendations, making it an essential dependency rather than an optional component.
Administrative access through kubectl configured to communicate with your target cluster is required since VPA installation creates cluster-wide resources including Custom Resource Definitions, RBAC permissions, and system-level components that operate across all namespaces.
You can verify that your cluster has metrics-server running with:
# Check if metrics-server is installed and running
kubectl get pods -n kube-system -l app.kubernetes.io/name=metrics-server
# Verify metrics collection is working
kubectl top nodes
kubectl top pods --all-namespaces
# Verify metrics are being served on v1beta1.metrics.k8s.io
kubectl get apiservices v1beta1.metrics.k8s.io
If metrics-server is not installed, you will need to install it first as VPA cannot function without access to resource consumption metrics:
helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/
helm repo update
helm upgrade --install metrics-server --namespace kube-system \
metrics-server/metrics-server
Note: On a testing cluster such as kind, you may also need to include --set args={--kubelet-insecure-tls}.
Step-by-step VPA installation
Clone the official autoscaler repository to access the VPA installation scripts and configuration files:
# Clone the Kubernetes autoscaler repository
git clone https://github.com/kubernetes/autoscaler.git
# Navigate to the VPA directory
cd autoscaler/vertical-pod-autoscaler/
Deploy VPA components using the provided installation script that creates all necessary resources:
# Install VPA using the installation script
./hack/vpa-up.sh
This deploys the three key VPA components (Recommender, Updater, and Admission Controller) into your cluster, installing them in the kube-system namespace alongside other cluster infrastructure components.
Verify successful installation by checking that all VPA components are running properly:
# Check VPA components are running
kubectl get pods -n kube-system | grep vpa
# Expected output shows three VPA components
vpa-admission-controller-xxxxx 1/1 Running 0 2m
vpa-recommender-xxxxx 1/1 Running 0 2m
vpa-updater-xxxxx 1/1 Running 0 2m
# Verify VPA Custom Resource Definition was created
kubectl get crd | grep verticalpodautoscaler
The successful installation creates the VerticalPodAutoscaler CRD that allows you to define VPA resources for your workloads, along with the necessary RBAC permissions and webhook configurations that enable VPA operation.
Alternative installation methods
Cloud provider installations often provide simplified approaches for managed Kubernetes services. Google GKE includes enhanced VPA capabilities, whilst Amazon EKS and Azure AKS support VPA through manual installation with provider-specific considerations for networking and permissions.
Helm chart installations provide an alternative to the shell script approach, offering more control over configuration values and integration with existing Helm-based deployment workflows. The official VPA project doesn’t provide an official Helm chart, but several well-maintained community options exist:
- Fairwinds VPA Chart: A production-ready chart from Fairwinds that includes comprehensive RBAC configuration, health checks, and testing capabilities:
helm repo add fairwinds-stable https://charts.fairwinds.com/stable
helm repo update
helm install vpa fairwinds-stable/vpa --namespace kube-system \
--create-namespace --version 2.0.0
helm test vpa -n vpa
- stevehipwell VPA Chart: A well-maintained chart with advanced features like cert-manager integration and webhook certificate management:
helm repo add stevehipwell https://stevehipwell.github.io/helm-charts/
helm repo update
helm upgrade --install vertical-pod-autoscaler \
oci://ghcr.io/stevehipwell/helm-charts/vertical-pod-autoscaler \
--namespace kube-system --create-namespace --version 1.9.3
Both charts provide production-ready configurations with proper security contexts, resource limits, and monitoring integration, making them suitable alternatives to the script-based installation for teams already using Helm for infrastructure management.
After successful installation, you can immediately begin creating VPA resources to observe recommendations for your workloads, starting with the Off mode configurations we explored earlier to build familiarity with VPA analysis before enabling any automated changes.
Next steps with VPA
Kubernetes VPA provides a systematic solution to the resource allocation challenges that affect every Kubernetes deployment at scale, transforming conservative guesswork into data-driven resource recommendations that deliver significant cost savings whilst improving application performance and operational efficiency. The evolution from experimental component to production-ready platform makes VPA adoption both safer and more valuable than ever before.
The transformation from manual resource allocation to automated optimisation requires understanding VPA’s capabilities, appropriate use cases, and implementation approaches that align with operational requirements and risk tolerance. Starting with observation mode allows teams to evaluate VPA effectiveness whilst building the confidence needed for broader adoption across production workloads without risking service disruption or performance degradation.
The systematic approach we have explored, from understanding the fundamental resource allocation problem through component architecture and installation to practical implementation, provides the foundation for successful VPA adoption that delivers measurable benefits whilst maintaining operational control and reliability.
However, this is not new information, we know; understanding the basics is just the beginning. In Part 2 of this series, we will dive deep into VPA’s component architecture, exploring how the Recommender, Updater, and Admission Controller work together to deliver reliable resource optimisation. We will examine configuration strategies, resource policies, and operational patterns that enable successful VPA deployment in complex production environments where reliability and performance are non-negotiable.
Frequently Asked Questions
Do I need to install anything before VPA will work on my cluster?
Yes, VPA requires metrics-server to be installed and running on your cluster as it provides the resource consumption data that VPA analyses. Most managed Kubernetes services include metrics-server by default, but you can verify it is working with kubectl top nodes. You will need Kubernetes 1.11 or later and cluster admin permissions for the installation.
Is VPA included with Kubernetes, or do I need to install it separately?
VPA does not come with Kubernetes by default, but is a separate project that must be installed manually. This differs from HPA, which is built into Kubernetes. You install VPA by cloning the kubernetes/autoscaler repository and running the installation script, which deploys the three VPA components (Recommender, Updater, and Admission Controller) to your cluster.
Can I use VPA alongside HPA for the same application?
You cannot use VPA with HPA when both target the same resource metrics (CPU or memory) as this creates scaling conflicts. However, they can work together when configured to manage different aspects - for example, VPA optimising memory allocation whilst HPA scales replicas based on custom metrics or different resource types. The key is ensuring they do not compete over the same scaling decisions.
How long does VPA need to run before it can make accurate recommendations?
VPA can start generating recommendations within 24 to 48 hours, but recommendation quality improves significantly with longer observation periods. VPA maintains 8 days of historical data by default, and for production workloads, we recommend running in Off mode for at least a week to evaluate recommendation stability before enabling automation, particularly for applications with weekly usage patterns.
Will VPA cause service disruption when it optimises my pods?
As of Kubernetes 1.33, VPA still requires pod recreation to apply resource changes, which can cause brief service disruption. However, VPA respects Pod Disruption Budgets to maintain availability during updates. The upcoming in-place pod resizing feature will eliminate most disruption scenarios, and you can always use Initial mode to apply optimisations only to new pods without affecting running services.
Additional Resources
- Kubernetes Vertical Pod Autoscaler Official Documentation
- VPA Quick Start Guide
- Kubernetes Resource Management Best Practices
- In-Place Pod Resizing Documentation (requires Kubernetes 1.33+)
This blog is part of our Vertical Pod Autoscaling series, we recommend reading the rest of the posts in the series:
- Understanding Kubernetes VPA: Why manual resource allocation is costing you thousands
- VPA component deep dive: How Kubernetes Vertical Pod Autoscaler works
- VPA production deployment: Avoiding pitfalls for safe and effective scaling
- Advanced VPA implementation: Production patterns, ecosystem tools, and real-world configuration