
LitmusChaos: Chaos Engineering with Helm Chart Test Suite
Explore how LitmusChaos uses Helm charts to enable chaos engineering for resilient Kubernetes systems
Written by:
Published on:
Last updated on:
What is Chaos Engineering?
Chaos engineering is the practice of performing experiments on your systems (e.g. applications) to identify whether or not your system is resilient, and LitmusChaos is a tool that makes it possible to perform chaos engineering within a Kubernetes cluster. To be specific it is a toolset developed to help Kubernetes developers and Site Reliability Engineers (SREs) practice chaos engineering with Kubernetes. Developers would run the chaos experiments during development as part of unit testing or integration testing (or as part of a CI pipeline), whilst SREs would run the chaos experiments against the application and/or the surrounding infrastructure. Both sets of users using chaos engineering with Litmuschaos will lead to resilient infrastructure and applications being developed.
Litmuschaos
Litmuschaos makes this possible by extending the Kubernetes API with additional Custom Resource Definitions (CRDs) that can be used to create, manage and monitor the chaos experiments. The three main CRDs are:
- ChaosExperiment
- Contains low-level execution details for running an experiment
- It is a template that can be reused
- ChaosEngine
- Hold information about how the chaos experiments are executed
- Connects an application instance with one or more chaos experiments
- Also contains status of the chaos experiments (after they are run)
- ChaosResult
- Holds the result of a chaos experiment
Along with these CRDs is a Litmuschaos Kubernetes Operator that will search for active ChaosEngines and will invoke the ChaosExperiments declared in the engine.
You can create your own custom chaos experiments to use, but the LitmusChaos team have created a list of generic/common experiments that can be used. The experiments can be found in the ChaosHub. Some examples of common experiments are:
- Injecting packet loss into an application’s pod
- Consuming CPU resources in an application’s container
- Causing a pod to fail
- Introducing IO Disk stress on a Kubernetes node
This demo will be using one of the provided experiments to fail an application’s pod as part of a Helm chart test suite.
Helm Chart Tests
When you package your Kubernetes application into a Helm chart you may also choose to include a test suite for the Helm chart to validate your deployed Helm charts.
A good use case for this is to perform a health check against your Kubernetes application (deployed via a Helm chart). However, imagine you have an application that is fully functional when it’s initially deployed but loses some (or all) of its functionality when a disaster strikes. For example, can we be confident that our application will still be fully functional if a pod crashes and restarts?
Ideally, we’d want a test suite that can also prove that an application is resilient and by packaging LitmusChaos experiments into a Helm chart test suite, it should be possible to create a test suite that can prove an application is resilient within a Kubernetes cluster.
Before going over the implementation details, I want to provide an overview of the workflows we’ll be combining, followed by the new workflow.
Workflows
Chaos Experiment Workflow
Assuming the litmuschaos operator is deployed, the workflow of a chaos experiment (via terminal only) is as follows:
- Deploy reusable
ChaosExperiments - Deploy an active
ChaosEnginewhich declares whichChaosExperimentsto use - The experiments are run automatically and
ChaosResultsobjects are created - Manually examine the
ChaosEngineandChaosResultsobjects to discover the results of the experiments
Note: Deployments can be done with the kubectl apply -f command
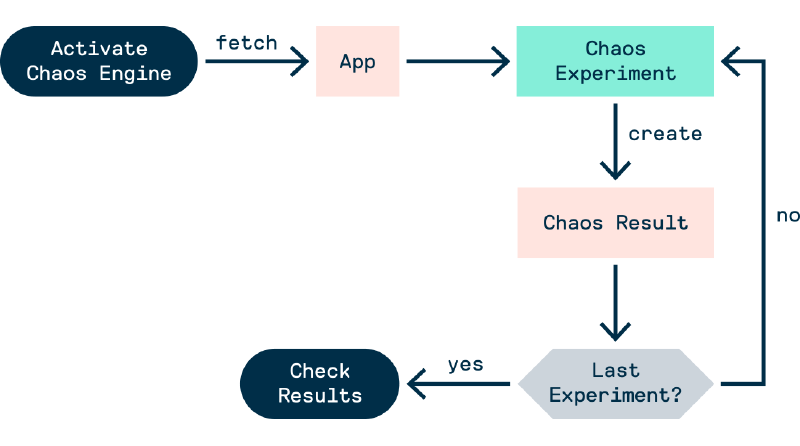
Figure - Chaos Experiment Workflow 1
Packaging the chaos experiments into a Helm chart test suite will improve this workflow. Some benefits include:
- Bundling all necessary resources for the chaos experiments together and have them deployable with a single command
- Making it possible to output the results of the chaos experiments after they are completed
- Having access to the Helm template engine to render the chaos experiments for different variations of the Kubernetes application packaged (i.e. different releases of a Helm chart)
So including the experiments in a Helm chart test suite will not only improve the test suite it’ll also improve the workflow of the chaos experiments. A win-win for both tools.
Now, we’ll go over the workflow for a Helm chart test suite.
Helm Chart Test Workflow
Tests in a helm chart live in the templates/ directory. Therefore, when creating a helm chart we need to create a template for a Pod and Job with the helm.sh/hook: test annotation. This annotation declares that the manifest file should be run/deploy when it’s time for Helm’s test hook to be invoked, which is when the helm test command is run.
The workflow for running a Helm test suite is:
- Deploy the helm chart (note: resources with the
helm.sh/hook: testannotation will not be deployed) - Run the
helm testcommand to invoke thetesthook - All resources with the
helm.sh/hook: testannotation will be deployed, this includes thePod(s) and/orJob(s) that will run the containers with the tests - Once all the containers are finished and have terminated the test results are outputted. If all the containers terminated successfully (i.e.
exit 0) then all tests passed.
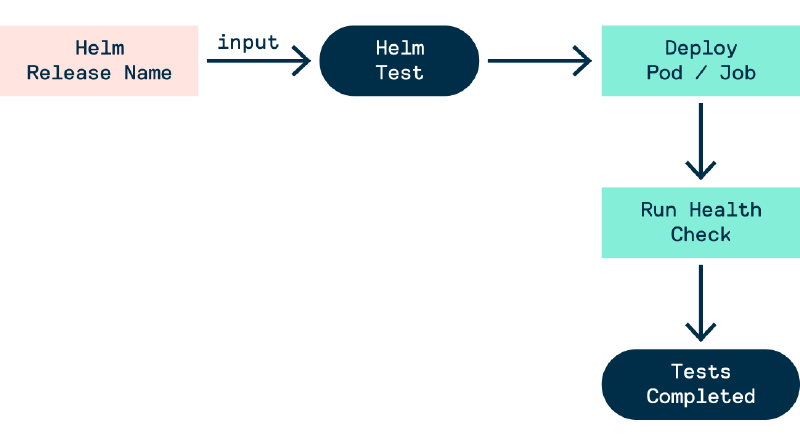
Figure - Chaos Experiment Workflow 2
With chaos experiments, the result of the experiments can be used to determine how the container should terminate.
New Workflow (Helm + LitmusChaos)
When we package LitmusChaos experiments into a Helm chart test suite, we can achieve the following workflow:
- Deploy reusable
ChaosExperiments - Run
helm test RELEASE_NAME --logs --debug - A
PodorJobobject is deployed, which will set theChaosEngineto active and then go through 3 phases- Perform a health check for the app
- Query the results of the chaos experiments
- Re-perform a health check for the app after the chaos experiments
- If a phase is unsuccessful (e.g. the chaos experiment fails) then the container will terminate, but not successfully. If all the chaos experiments pass and the two app health checks were successful then the test suite was successful.
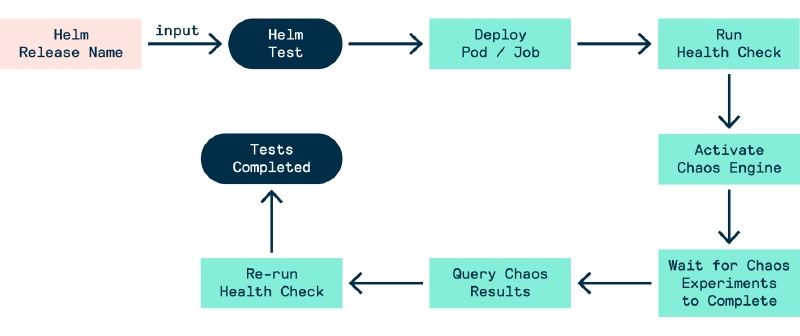
Figure - Chaos Experiment Workflow 3
Technical/Implementation Details
Now the question is how do we create this new workflow?
Prerequisites
First, we’ll need the prerequisites:
- The
ChaosEngineand the necessary RBAC objects run the experiments should be deployed as part of the helm chart - The
ChaosEngine’sengineStateshould be stopped bystopby default - The chaos reporter (i.e. the
Pod/Job) must:- use an image with the command line tools
bash,curlandjq - contain the helm test hook annotation:
helm.sh/hook: test - have permission to
GETandPATCHtheChaosEnginesresults via the Kubernetes API (i.e. the necessary RBAC objects should be deployed as part of the helm chart)
- use an image with the command line tools
The Chaos Reporter: Querying Chaos Experiments
With the prerequisites set up, we now need to define the container within the Pod/Job that will execute the tests. The tests will be in one bash script and will involve repeatedly running the curl command against the kubernetes.default.svc DNS name, which is the recommended approach to querying the API within a pod. With these curl commands, we’ll be able to patch and query the ChaosEngine.
At the start of the script, we’ll need to fetch the token of the service account within the pod. We will need this token to run our curl commands with the correct permissions assigned to the service account.
KUBE_TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
curl -sSk -H "Authorization: Bearer $KUBE_TOKEN" $URL
The URL follows the convention https://kubernetes.default.svc:443/apis/$GROUP_NAME/$VERSION/$NAMESPACE/$RESOURCE_TYPE/$RESOURCE_NAME
In this case:
- The group name is
litmuschaos.io - The version is
v1alpha1 - The resource type is
chaosengine - The namespace and resource name can be anything
The output of the curl command would be a description of the deployed ChaosEngine - which includes the engine status, the chaos experiments and the results of the experiments.
Starting & Stopping Chaos Experiments
To start the experiment by patching the ChaosEngine we’ll need to modify the curl command to:
- Set the
Content-Typeheader toapplication/json-patch+json - Set the request type to
PATCH - Provide data for the patch request
An example is below:
curl -sSk -H "Authorization: Bearer $KUBE_TOKEN" \
-H "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "replace", "path": "/spec/engineState", "value": "active"}]' \
$URL
To stop the ChaosEngine you would set the value to stop instead of active.
Test Algorithm
Now that we’re aware of how to get a pod to query and patch the ChaosEngine we can define the following algorithm for our tests:
- Run app health check
- Patch the
ChaosEngineand activate/trigger the experiments - Continuously poll the
ChaosEngineuntil the experiments arecompleted - Get the verdict/result of all the chaos experiments
- Patch the
ChaosEngineand disable/stop the experiments - Re-run app health check
You can find example code for this (and the helm chart) here. The gif below is a demonstration of the workflow in action.
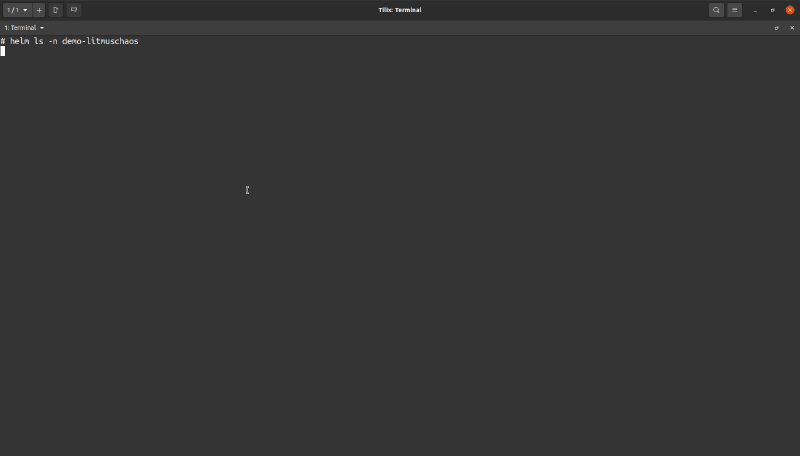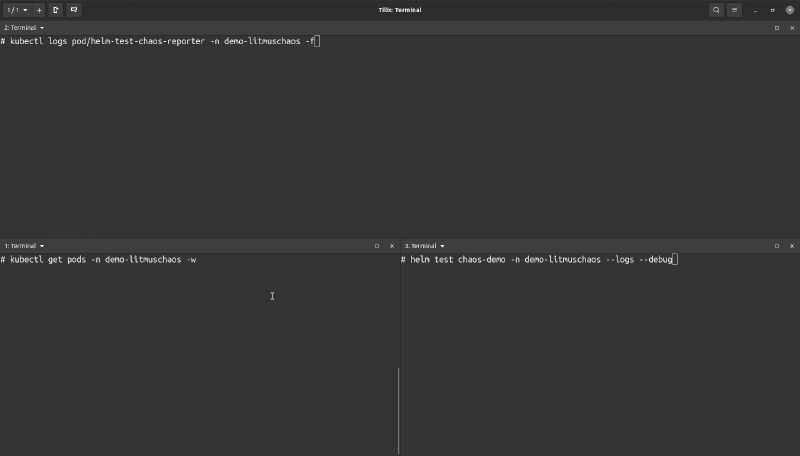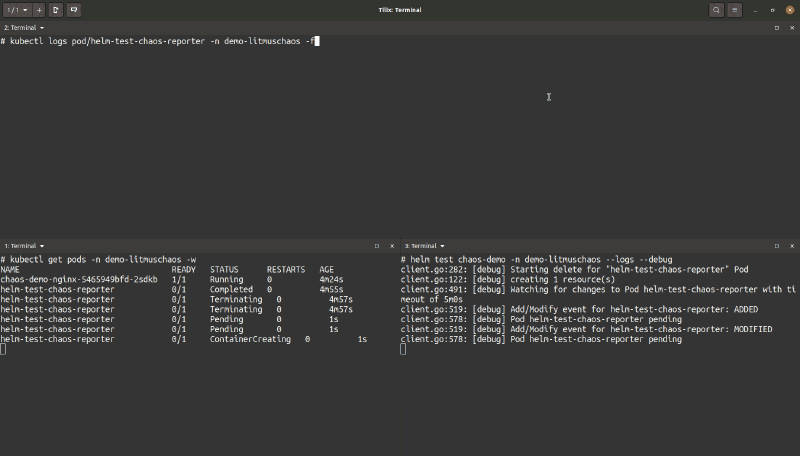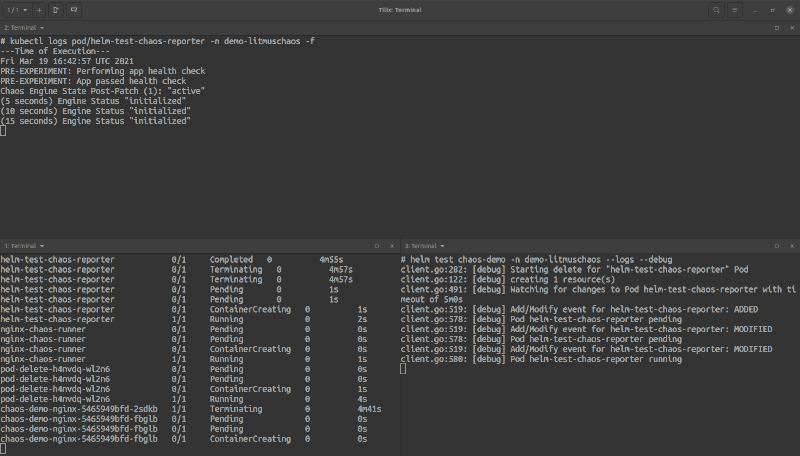
The experiment would take at least a minute to complete, so the gif was cut short. In the gif, you saw the logs for the tests were in the helm-test-chaos-reporter pod. If you used the --logs flag with helm test the logs will be shown as the output (alongside other details) of the helm test command once the test either passes or fails (The image below shows the tail end of the output).
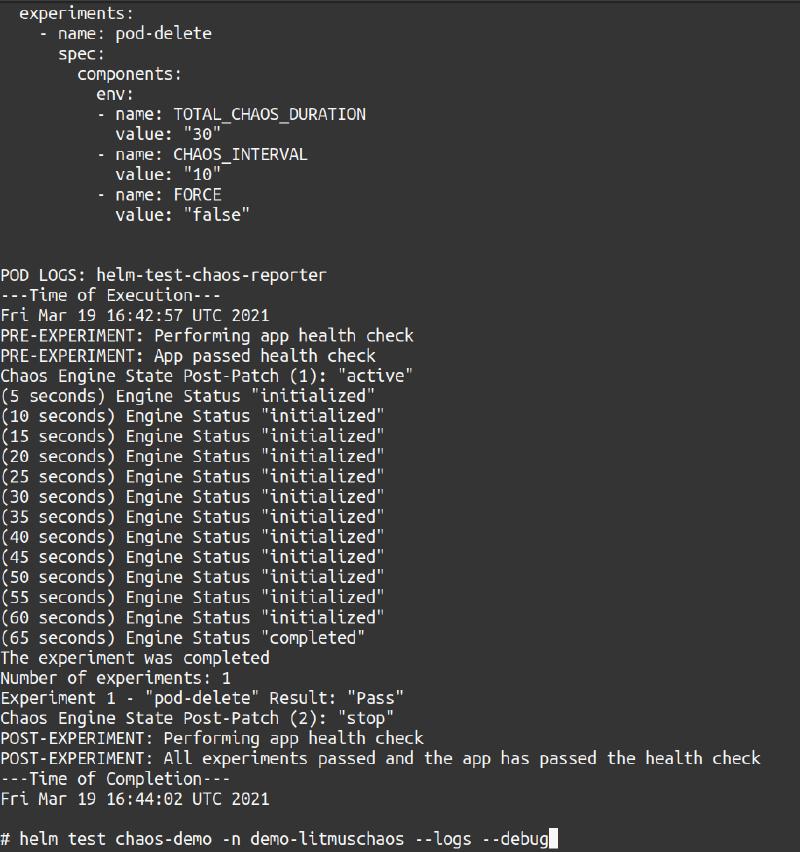
Figure - Last output of the workflowe
Final thoughts on LitmusChaos from a DevOps engineer
This is as far as we’re going to go with LitmusChaos today, but by combining LitmusChaos with Helm we’re able to easily configure chaos experiments for specific Helm charts/releases (i.e. Kubernetes applications) and run them.
With this approach and the right chaos experiments Helm chart maintainers will be able to create a test suite to confirm the resilience of the Kubernete application deployed as part of a Helm chart and include this test suite within a CI pipeline that’ll be able to provide ample feedback to developers.
We’re looking forward to integrating this new workflow in our internal projects and exploring the other CNCF sandbox projects.