
Running Docker containers on Apache Mesos
Introduction to Docker containers on Apache Mesos allowing DevOps engineers to run applications at scale
Written by:
Published on:
Feb 4, 2015Last updated on:
Jul 8, 2025DevOps Philosophy
In the past, pushing your application from development into a production environment was a nightmare. Deployments would fail as developers would forget an obscure dependency that crept in to the project months ago, and provisioning a new machine with the correct environment could take hours! The world of technology moves too fast for this to be acceptable, so in recent years, the “DevOps philosophy” has emerged, a process where both development and operations engineers take part in the whole product life cycle. One of the questions that has emerged from this school of thought is, “Why can’t I push the app I’ve been testing on my personal machine straight into our production environment?” A number of tools have emerged to try and fulfil this need, and we’ll be looking at Docker in this post.
Docker
Docker is a lightweight container virtualisation platform, originally based on LXC, but it now uses libcontainer. In a nutshell, Docker provides process, file system and network isolation between processes by leveraging the namespaces feature of the Linux kernel. As a full-blown hypervisor is unnecessary, containers are extremely quick to create and have virtually 0 overhead.
Containers are useful because they vastly simplify deployment. In the past, deploying meant packaging your application, specifying a list of dependencies, and then having to rely on the target server’s package manager to create a working environment. This generally leads to problems down the line, as a library update initiated by your security team breaks your app and you suddenly have to debug a live server remotely. With containers, you package your entire app into 1 unit. This unit will run in an identical way on any host it is deployed on, meaning that pushing your app to production is just 2 or 3 commands.
While you can manage containers manually using LXC commands, Docker adds a number of neat features that make it worth using:
- Version control / Registries:
- Containers are constructed from a series of layered file systems, and each layer is tagged and committed to a registry. This means that updating your app to a newer version is extremely fast, as only the files that are changed need to be pushed, as the rest is cached.
- Automatic network configuration:
- Docker manages NAT for your containers, allowing multiple containers to run that would usually want to listen on the same port on one host (e.g. multiple web server containers.).
- Persistent volumes / mount host volumes:
- Persistent volumes can live on top of the layered file system so they persist across container restarts, or you can mount a file descriptor from the host directly in to the container.
- Client / server architecture:
- The Docker daemon can be managed over a Unix or TCP socket. If you want to manipulate containers from within a container, you can just mount the Docker unix socket from the host into the container!
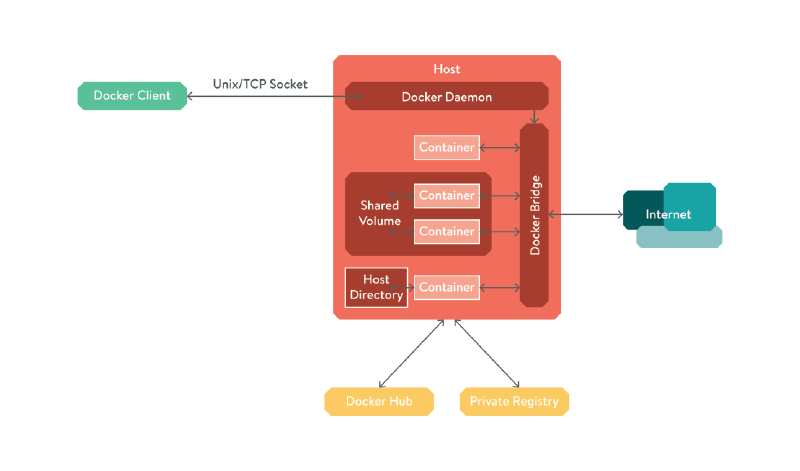
Figure - Docker diagram
Packaging an application for deployment goes something like this:
- Create container from a base container, e.g. Ubuntu.
- Install your app dependencies, commit.
- Add your app, commit.
- Push the container to your private registry (or the public Docker Hub)
- Then on the server, pull your container and start it!
Step 5 can be easily done over SSH when you have a single instance, but what if we want hundreds? One of the benefits of containers is they are discrete units with no external dependencies, so we can easily scale them up. Introducing…
Mesos
Apache Mesos is a project that turns a group of interconnected servers into one abstract block of resources, with optional amounts of redundancy coordinated through Apache ZooKeeper. In production, you would run 3 or 5 masters, depending on whether you want to tolerate 1 or 2 consecutive failures, and as many slaves as you felt the need to. If you need more resources, simply spin up more slaves, and turn them off again when you no longer need them. As machines are paid for by the hour, you can keep costs low while also having the ability to scale quickly under a sudden influx of traffic.
Mesos is made up of 3 key components:
- Master - a daemon that manages slave daemons
- Slave - a daemon that runs tasks on a host
- Framework - a.k.a. a Mesos application. This consists of a Scheduler and one or more Executors:
- Scheduler - Registers with the master to obtain resource offers
- Executor - Runs on the slaves to launch a task
The Mesos master will periodically make resource offers to any registered framework, and the framework’s scheduler can choose to accept it and launch a task. In our case, we will be using the Marathon framework to launch docker containers, so our whole system will look something like this:
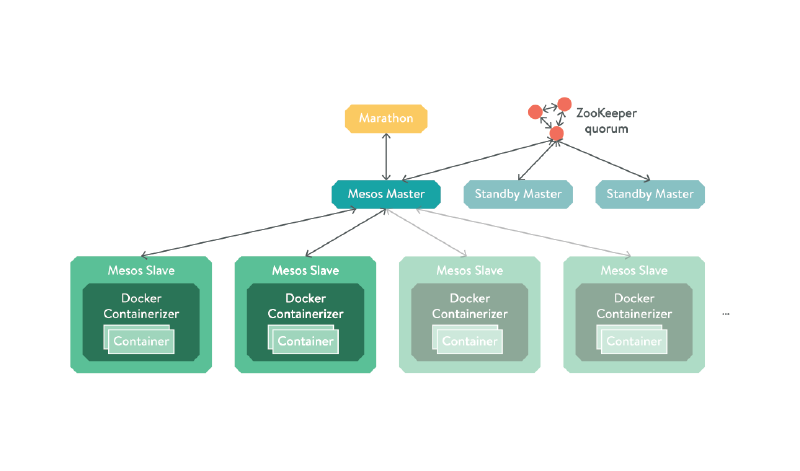
Figure - Marathon diagram
The Marathon framework is a process scheduler for long running tasks, similar to init or upstart, but designed for use
on a Mesos cluster. While it has a web interface, at the time of writing you cannot create docker containerised tasks
from it, so we have to create them by sending JSON files describing our application to Marathon’s HTTP API.
Here is an example nginx.json configuration for nginx:
{
"id": "demo-nginx",
"cpus": 0.1,
"mem": 64.0,
"instances": 2,
"container": {
"type": "DOCKER",
"docker": {
"image": "nginx:latest",
"network": "BRIDGE",
"portMappings": [
{
"containerPort": 80,
"hostPort": 0,
"protocol": "tcp"
}
]
}
},
"healthChecks": [
{
"protocol": "HTTP",
"portIndex": 0,
"path": "/",
"gracePeriodSeconds": 5,
"intervalSeconds": 20,
"maxConsecutiveFailures": 3
}
]
}
curl -X POST \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
http://address.of.marathon:8080/v2/apps \
-d @nginx.json
This example will launch 2 instances of the docker container nginx:latest somewhere on the cluster, and NAT a random
port on the host to port 80 in the container. You can make sure they’re running by viewing their tasks in the
Mesos Web UI.
Bamboo: Marathon-aware Load Balancer
Now we have several instances of our container running somewhere in our cluster, but we have no idea which physical host Mesos has launched them on, nor the ports it has chosen. The final piece of the puzzle is Qubit Products’ Bamboo, which is a Mesos aware config file generator for HAProxy. Simply edit the address of ZooKeeper in their config file, and it will automatically discover all the services you have running on your cluster, and configure HAProxy to point at them!
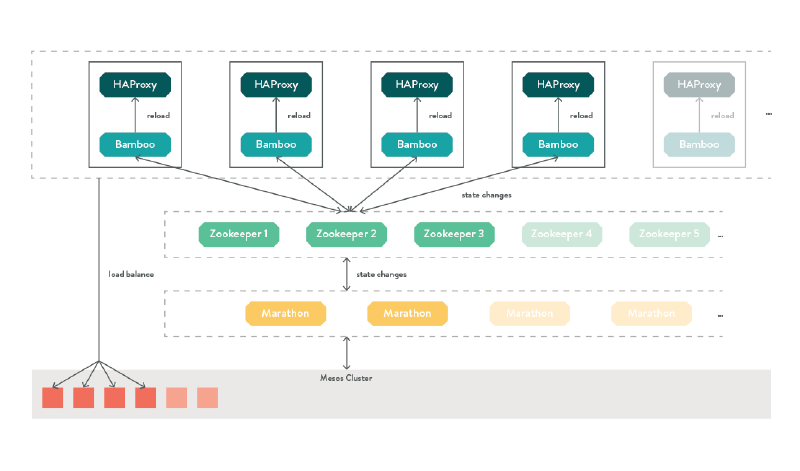
Figure - Bamboo diagram
DevOps Engineer Summary
This article barely scratches the surface of large scale deployment. Real-world applications are not always able to be condensed into a single unit, and something like a database cannot be scaled up just by spawning more processes. In subsequent posts, we will explore various other technologies surrounding containers at scale, and examine solutions, pitfalls and best practices to splitting a complex application into discrete, scalable containers.